Appearance

State-Space Models vs Transformers: Can SSMs Really Replace Attention?
A clear breakdown of how State-Space Models (SSMs) like Mamba work, how they differ from Transformers, and whether they can realistically replace attention-based AI models in 2026.
If you have ever waited longer for an AI model to respond simply because you fed it a longer document, you have felt the Transformer's biggest weakness firsthand. The longer the input, the more expensive every single step becomes. This is not a bug. It is baked into how attention works.
For years, that tradeoff felt unavoidable. Bigger context meant bigger bills and slower responses, full stop. Researchers tried trimming, caching, and approximating attention, but the core math stayed the same: cost grows quadratically with sequence length.
That is where State-Space Models (SSMs) come in. They borrow ideas from old-school control theory and rebuild sequence modeling from scratch, with cost that grows linearly instead of quadratically. This post breaks down what SSMs actually are, how they stack up against Transformers, and why most of the AI industry is not picking one over the other, but blending them.
What Is a Transformer, Quickly
A Transformer reads a sequence by letting every token "look at" every other token. This is called self-attention.
It is powerful because it captures relationships between any two points in a sequence, no matter how far apart they are. That is why Transformers are so good at reasoning and precise recall.
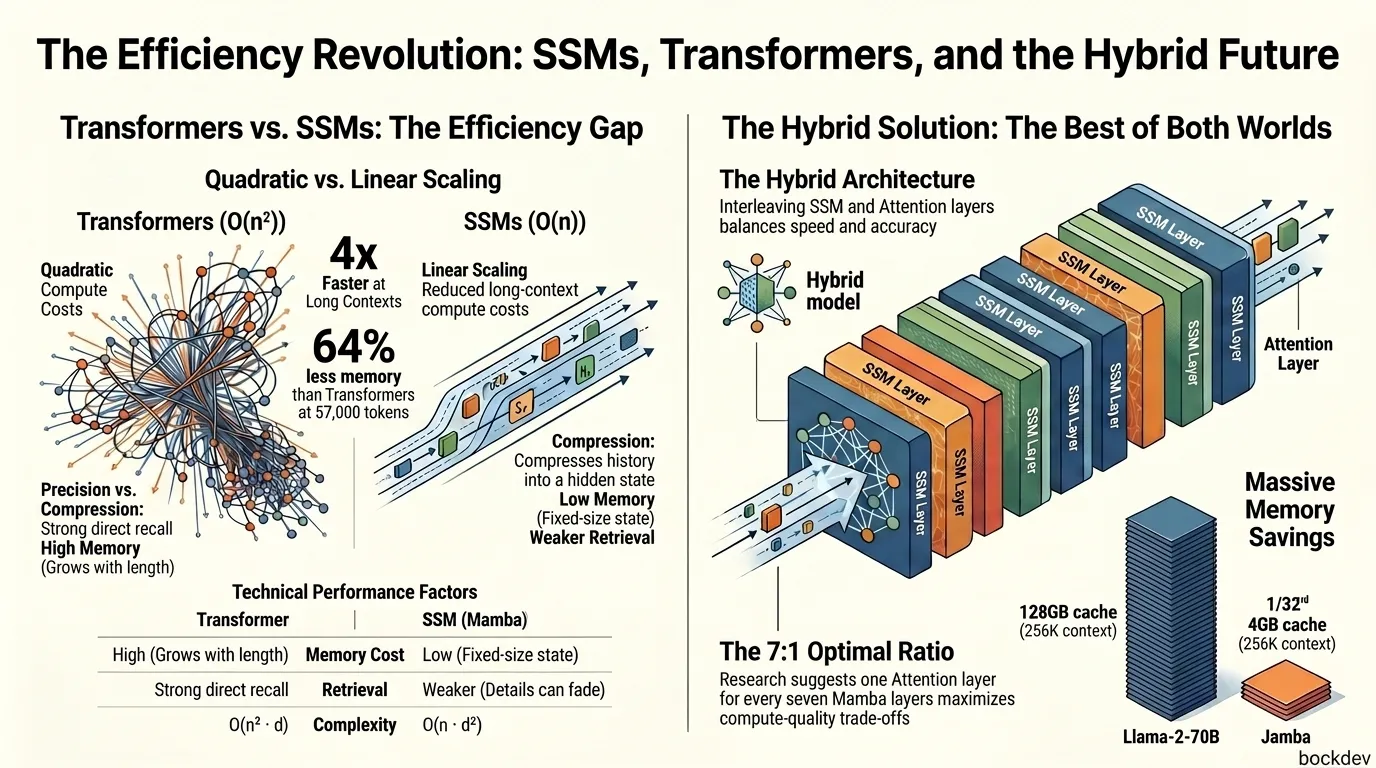
The catch is cost. Attention scales quadratically with sequence length, so doubling the tokens in a context window quadruples the compute needed. At a few thousand tokens, that is fine. At 100,000+ tokens, it becomes expensive fast.
What Is a State-Space Model
SSMs did not start in AI. They come from control theory, the engineering field used to model physical systems like aircraft and robotic arms.
The core idea: instead of comparing every token to every other token, an SSM keeps a single compressed "state" that updates as each new token arrives.
An SSM processes tokens one by one, updating a compressed hidden state rather than attending over all previous tokens simultaneously. Think of it like reading a book and updating a short mental summary after each page, instead of re-reading every previous page each time.
Because the model never has to revisit the whole sequence, the math scales linearly. SSMs operate with a complexity of O(n · d²), much friendlier than the O(n² · d) complexity of self-attention.
Why SSMs Got Serious: Mamba
Early SSMs (like S4) worked but had a weakness: their internal "filters" did not adapt to the input. SSMs compute their output as a weighted sum of input tokens, but unlike Transformers, those weights did not depend on the input itself, which limited how much they could express.
Mamba fixed this with selective state updates. It introduces input-dependent gating, letting the model dynamically control how information flows through its state, so it can choose what to remember and what to forget based on what it is actually reading.
That single change made SSMs competitive with Transformers for the first time on real language tasks, not just toy benchmarks.
SSMs vs Transformers: Strengths and Weaknesses
Neither architecture wins everywhere. Here is the honest tradeoff:
| Factor | Transformer | SSM (Mamba-style) |
|---|---|---|
| Compute scaling | Quadratic (O(n²)) | Linear (O(n)) |
| Long-context memory cost | High, grows with sequence length | Low, fixed-size state |
| Precise fact retrieval | Strong, attends directly to every token | Weaker, older details can blur or fade |
| Speed on short sequences | Faster | Slower (sequential processing overhead) |
| Speed on long sequences | Slower | Much faster |
| Best-known weakness | Memory and cost at scale | Copying/state-tracking tasks |
The retrieval gap is well documented. Because attention connects every token to every other token directly, a Transformer can pull a specific fact from early in a long document with high accuracy, while an SSM's compressed state means older details can blur together or fade. This is why "Needle in a Haystack" tests, where a fact is hidden inside a huge document, consistently favor Transformers.
SSMs also struggle with tasks that need exact copying. Research has shown SSMs are inferior to Transformers when asked to simply copy an input sequence, because a single SSM layer cannot dynamically pick which tokens to extract the way attention can.
But on raw efficiency, the numbers favor SSMs hard at scale. While Transformers are up to 1.9x faster at short sequences under 8K tokens, SSMs become up to 4x faster at long contexts around 57,000 tokens, with roughly 64% lower memory use.
Where SSMs Already Win Today
Some domains are a near-perfect fit for SSMs because the sequences are extremely long and structured.
- Genomics: DNA sequences can run hundreds of thousands of base pairs long, and SSM-based models handle these lengths in ways Transformers simply cannot afford computationally.
- Audio and speech: long, continuous signals benefit from linear-time processing.
- Code and logs: Mamba-style models are well suited to long files where structure matters more than pinpoint recall of one line.
The Real Trend: Hybrid Models, Not a Clean Winner
Here is the part most "SSM vs Transformer" debates skip: almost nobody is betting on pure SSMs replacing Transformers outright. The industry is building hybrids.
The most well-known example is Jamba from AI21 Labs. Jamba is the first production-grade Mamba-based model, built on a hybrid SSM-Transformer architecture, offering a 256K context window and 3x the throughput of Mixtral 8x7B on long contexts.
The architecture interleaves layer types instead of picking one. Each Jamba block mixes Mamba and Attention layers at a ratio, followed by an MLP, and that ratio can be tuned to balance memory usage, training efficiency, and long-context capability.
The released configuration uses a heavily Mamba-biased mix. The model employs a 1:7 attention-to-Mamba ratio, meaning for every eight sequential layers, one is a Transformer attention layer and the other seven are Mamba layers, chosen as a sweet spot between efficiency and quality.
The payoff shows up directly in memory. With a 256K token context, Jamba needs only about 4GB for its attention cache, compared to roughly 32GB for Mixtral and 128GB for Llama-2-70B.
Researchers studying these hybrids have found a clear pattern in how to split the work. For workloads dominated by local pattern recognition and generation, SSM-heavy layers are preferable, while workloads dominated by in-context learning and retrieval need more attention layers. Across studied models, a 7:1 Mamba-to-attention ratio sits near the optimal point on the compute-quality tradeoff curve.
This is the practical takeaway: SSMs are not "beating" Transformers. They are becoming the efficient backbone that lets Transformer attention be used sparingly, only where it actually earns its cost.
A Simple Way to Picture the Architecture
Pure Transformer Stack Jamba-style Hybrid Stack
┌─────────────────────┐ ┌─────────────────────┐
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Mamba Layer │
├─────────────────────┤ ├─────────────────────┤
│ Attention Layer │ │ Attention Layer │ ← 1 out of 8
└─────────────────────┘ └─────────────────────┘
Every layer is O(n²) Mostly O(n), attention used sparinglyTrying an SSM-Based Model Yourself
If you want to experiment with a real hybrid model, Jamba's base weights are open and usable through Hugging Face Transformers.
bash
pip install transformers torch mamba-ssm causal-conv1dpython
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/Jamba-v0.1",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)If memory is tight, you can quantize the model, but it is best to leave the Mamba layers untouched to avoid quality loss:
python
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_skip_modules=["mamba"] # skip quantizing Mamba blocks
)
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/Jamba-v0.1",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
quantization_config=quantization_config
)This setup lets you fit a much longer context window into a single GPU than a pure Transformer model of similar size would allow.
So, Will SSMs Replace Transformers?
Probably not outright, and that is fine. The more accurate framing is that SSMs are reshaping how Transformers get used, not erasing them.
Pure attention is increasingly hard to justify as context windows keep growing into the hundreds of thousands of tokens. But pure SSMs still give up too much precision on tasks like exact retrieval and copying. The hybrid path, a small amount of attention layered on top of a mostly-SSM backbone, is currently winning in production because it keeps the strengths of both and hides most of the weaknesses.
Q&A
1. What does SSM stand for in AI?
SSM stands for State-Space Model, an architecture that updates a compressed hidden state over time instead of comparing every token to every other token.
2. Is Mamba an SSM?
Yes. Mamba is a specific, improved type of SSM that uses input-dependent (selective) gating to decide what information to keep or drop as it processes a sequence.
3. Why are Transformers slow on long documents?
Because self-attention compares every token to every other token. Doubling the input length quadruples the compute needed, which is what makes very long context windows expensive.
4. Are SSMs faster than Transformers?
It depends on length. Transformers tend to be faster on short sequences, while SSMs pull ahead significantly at long sequences, since their cost grows linearly instead of quadratically.
5. Can SSMs replace attention entirely?
Not reliably yet. SSMs compress history into a fixed-size state, so exact fact retrieval and copying tasks suffer compared to Transformers, which attend directly to every prior token.
6. What is a hybrid SSM-Transformer model?
A model that mixes both layer types, using mostly SSM layers for efficiency and a small number of attention layers for accurate retrieval. Jamba is the best-known example.
7. What is Jamba?
Jamba is a production-grade language model from AI21 Labs that interleaves Mamba (SSM) layers with Transformer attention layers and Mixture-of-Experts layers, supporting context windows up to 256K tokens.
8. What tasks are SSMs best suited for?
Long, structured sequences such as genomic data, audio, and large codebases or logs, where the sequence is long but exact pinpoint recall of an early detail matters less.
9. Do I need special hardware to run SSM-based models?
You need a CUDA-capable GPU for the optimized Mamba kernels (via mamba-ssm and causal-conv1d). Running without them works but is much slower.
10. Is the SSM vs Transformer debate settled?
No. Most current research and production systems point toward hybrids rather than a single winner, since each architecture covers the other's weak spot.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model - https://www.ai21.com/blog/announcing-jamba/
- Characterizing State Space Model (SSM) and SSM-Transformer Hybrid Language Model Performance - https://arxiv.org/abs/2507.12442
- State Space Models (SSMs) & Alternatives to Transformers: Deep Diving into the Math Behind Mamba and S4 Architectures - https://billionhopes.ai/state-space-models-ssms-alternatives-to-transformers-deep-diving-into-the-math-behind-mamba-and-s4-architectures/