Appearance

Liquid Neural Networks (LNNs): AI That Adapts on the Fly
Liquid Neural Networks (LNNs) are continuous-time AI models that keep learning after deployment. Learn how they work, how they differ from regular neural networks, and where they are used.
Most AI models stop learning the moment training ends. You spend weeks feeding them data, then you ship them, and from that point on their behavior is locked in. If the real world looks even a little different from the training data, the model just gets it wrong. No adjustment, no second chance.
This is a real problem for anything that runs in a changing environment. A drone flying through a forest in summer will face a completely different scene in winter. A sensor on a factory floor will pick up new vibration patterns as machines age. A regular neural network has no way to handle that drift gracefully.
Liquid Neural Networks (LNNs) were built to fix exactly this. Instead of freezing after training, they keep adjusting their internal behavior based on whatever data comes in, even after deployment. Let's break down what that actually means and how it works.
What Makes a Neural Network "Liquid"
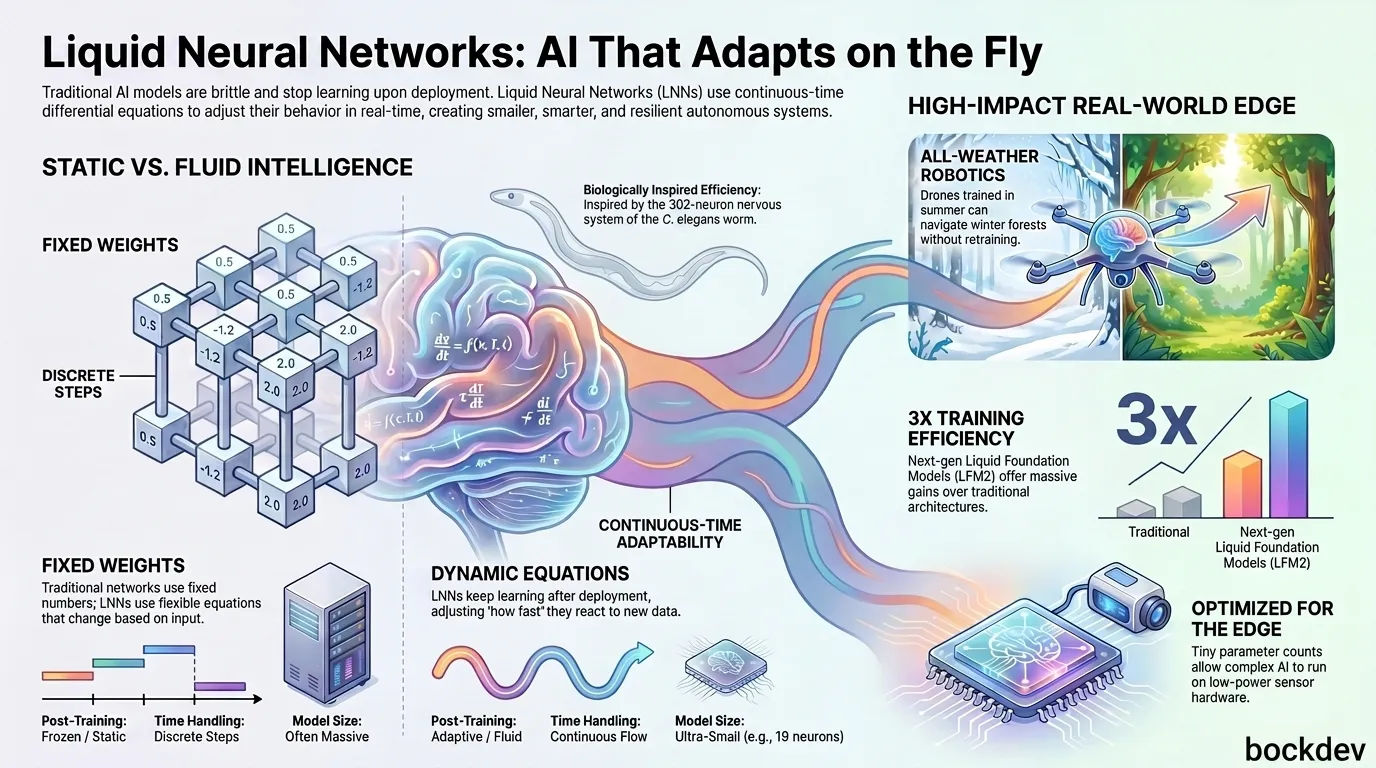
A normal neural network is made of fixed weights and fixed activation functions. Once training is done, those numbers don't change unless you retrain the whole thing.
An LNN works differently. Each neuron follows a small differential equation, and that equation includes a "time constant" that changes depending on the current input. This time constant is itself learned and depends on the state and input, which makes the network's effective behavior fluid rather than fixed.
In plain words: the network doesn't just react to data, it adjusts how fast and how strongly it reacts, based on what it's currently seeing. That's the "liquid" part.
The architecture was introduced by Ramin Hasani and collaborators at MIT in 2021 in the Liquid Time-Constant Networks paper. It takes inspiration from the nervous system of the C. elegans worm, which has only a few hundred neurons but processes information in a remarkably efficient way.
How LNNs Work, Step by Step
LNNs don't process data in fixed time steps like a regular RNN. Instead, they use continuous-time differential equations as their core computation, rather than the discrete steps used in conventional networks.
Here is the simplified flow:
- Input arrives (a sensor reading, a video frame, a sentence token).
- Each neuron updates its state using its own differential equation.
- The time constant adjusts itself based on the input and the neuron's current state. This controls how quickly the neuron "forgets" old information versus reacting to new information.
- The network produces an output, and the internal state carries forward to the next input.
Because step 3 happens continuously and dynamically, the network's behavior shifts smoothly as conditions change, instead of needing a full retrain.
There are two main practical variants you'll run into:
- LTC (Liquid Time-Constant): the original formulation, solved using numerical integration.
- CfC (Closed-form Continuous-time): computes the update in one closed-form step, which avoids numerical solvers and is faster to run.
LNNs vs Traditional Neural Networks
| Feature | Traditional Neural Network | Liquid Neural Network |
|---|---|---|
| Behavior after training | Fixed/frozen | Keeps adapting to new input |
| Computation style | Discrete time steps | Continuous-time differential equations |
| Parameter count | Often large | Very small (sometimes under 20 neurons for control tasks) |
| Handles changing environments | Poorly, needs retraining | Well, adapts without retraining |
| Best fit | Large-scale language/vision tasks | Sensor data, robotics, edge devices, time series |
| Interpretability | Often a black box | More transparent, easier to trace decisions |
In the original research, 19-neuron LNNs were able to match much larger conventional networks on autonomous driving control tasks. That's the kind of efficiency gain that makes LNNs attractive for devices that can't run huge models, aligning with the broader small-model renaissance where developers prioritize lightweight efficiency over raw parameter scale.
How LNNs Compare to Transformers and Other Modern Architectures
Transformers dominate AI right now, but they aren't free of trade-offs. Transformers need O(N²) computation and memory as sequence length grows, and pushing them further gives smaller accuracy gains for steadily rising compute cost. To address these resource demands, techniques like attention head pruning are often used to reduce model size.
LNNs take a different path. They win on parameter efficiency and interpretability for low-dimensional control tasks, but they have not scaled to large language modeling the way transformers have.
Here's a quick comparison of where each architecture tends to shine:
| Architecture | Strength | Weakness |
|---|---|---|
| Transformers | Long-context language and vision tasks | Heavy compute and memory cost |
| LNNs (LTC/CfC) | Tiny models, real-time adaptation, sensor/control tasks | Hasn't scaled to large language models |
| Mamba / State-Space Models | Efficient long sequences | Reaches efficiency through structured transition matrices, less biologically grounded |
| Hyena | Long convolutions with gated modulation, reaches near-linear complexity via FFTs | Less mature ecosystem |
The takeaway: LNNs are not trying to replace ChatGPT-style models. They're solving a different problem, running smart, adaptive AI on small, resource-limited devices. As developers hit the cloud-cost constraints of the token burn crisis, running lightweight, edge-native architectures like LNNs is becoming a key strategy.
Real-World Use Cases
LNNs show up wherever conditions change unpredictably and compute is limited:
- Drones and robotics: MIT's drone experiments showed LNN-powered agents navigating forests and urban environments better than other models when facing noise, occlusion, and rotation. This makes LNNs highly promising for mixed-criticality physical AI and robotics, where real-time safety control loops must share computing hardware with neural networks without interference.
- Time series forecasting: LNNs are used for stock price prediction, demand forecasting, and anomaly detection in sensor or vibration data.
- Wireless networks: A 2025 study looked at how LNNs help with robustness and interpretability challenges in wireless networks, showing improved performance in real case studies.
- Edge and embedded devices: because LNNs use far fewer parameters, they fit on hardware that can't run a full-size transformer.
- Supply chain and finance: hybrid models combine LNNs with gradient boosting for tasks like multi-tier ordering optimization.
Trying LNNs in Code
You don't need to build the differential equation solver yourself. The ncps library (from the original MIT research team) gives you ready-to-use LTC and CfC layers for both PyTorch and Keras.
Installation
bash
pip install ncps torchA Minimal CfC Example (PyTorch)
python
import torch
from ncps.torch import CfC
# input_size=20 features, 50 hidden units
rnn = CfC(20, 50)
# batch=2, time_steps=3, features=20
x = torch.randn(2, 3, 20)
h0 = torch.zeros(2, 50)
output, hn = rnn(x, h0)
print(output.shape) # torch.Size([2, 3, 50])Using the LTC Variant Instead
python
from ncps.torch import LTC
input_size = 20
units = 28 # 28 neurons, similar scale to the original driving experiments
rnn = LTC(input_size, units)A Simple Project Structure for an LNN Time Series Project
lnn-project/
├── data/
│ └── sensor_readings.csv
├── models/
│ └── ltc_model.py
├── train.py
├── evaluate.py
└── requirements.txtpython
# train.py (simplified)
import torch
import torch.nn as nn
from ncps.torch import CfC
model = CfC(input_size=10, units=32)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()
for epoch in range(20):
optimizer.zero_grad()
output, _ = model(x_batch)
loss = loss_fn(output, y_batch)
loss.backward()
optimizer.step()That's it. The library handles the differential equation math internally, so from a usage standpoint it behaves like any other RNN layer.
Where the Field Is Heading
LNN research has moved beyond pure academia. The team behind the original research spun out a company called Liquid AI, which is now building Liquid Foundation Models (LFMs) designed to run efficiently on consumer-level hardware. In July 2025, Liquid AI released LFM2, a second-generation model reported to offer twice the decode and prefill performance of competitors on CPUs, and three times better training efficiency than its predecessor.
The company has also partnered with AMD to optimize these models across CPUs, GPUs, and neural processing units, tailoring the algorithms to the underlying hardware. A recent funding round valued the company at over $2 billion, signaling that liquid networks are moving from research labs into commercial products.
Current research is also pushing into uncertainty-aware variants. One model, UA-LNN, adds uncertainty quantification on top of the standard LNN, improving reliability specifically when data is noisy or incomplete.
Limitations to Keep in Mind
LNNs are not a universal upgrade over every other architecture. A few honest limitations:
- They have not been scaled to compete with large language models the way transformers have.
- Training involves solving differential equations, which can be slower than standard backpropagation unless you use closed-form variants like CfC.
- The ecosystem (tooling, pretrained models, community support) is much smaller than for transformers.
- They shine in low-dimensional, sequential, or control-style tasks, not necessarily in massive multi-modal tasks.
Wrapping Up
Liquid Neural Networks solve a problem that regular neural networks were never built to handle: staying useful when the world keeps changing after deployment. By using continuous-time math instead of fixed weights, they adjust their own behavior in real time, all while staying small enough to run on edge devices.
They won't replace transformers for language tasks anytime soon. But for robotics, sensors, drones, and anything that has to keep working as conditions shift, LNNs are one of the more promising directions in AI right now.
Q&A
1. What does "liquid" actually mean in Liquid Neural Networks?
It refers to the network's time constant, the value that controls how fast a neuron reacts, changing dynamically based on input. This makes the network's behavior fluid instead of fixed.
2. Are LNNs better than transformers?
Not universally. LNNs are more efficient for small, sequential, or control tasks. Transformers are still better for large-scale language and vision tasks.
3. Do LNNs need to be retrained to adapt to new data?
No. That's the main point. They adjust their internal dynamics on the fly without a full retraining cycle.
4. What's the difference between LTC and CfC?
LTC is the original formulation, solved with numerical integration. CfC computes the update in one closed-form step, making it faster and easier to train.
5. Can I run an LNN on a Raspberry Pi or similar edge device?
Yes. Their small parameter count is one of their biggest selling points for resource-constrained hardware.
6. What library should I use to get started?
ncps, built by the original research team, supports both PyTorch and Keras with ready-made LTC and CfC layers.
7. Are LNNs only for robotics?
No. They're also used in time series forecasting, anomaly detection, wireless network optimization, and finance.
8. Is Liquid AI the same thing as the LNN research?
Liquid AI is a company spun out of the original MIT research team, now building commercial Liquid Foundation Models (LFMs) based on the same core ideas.
9. Do LNNs require special hardware?
No special hardware is required, though their efficiency makes them especially well suited for neuromorphic and edge hardware.
10. Are LNNs harder to train than normal neural networks?
Training can be more computationally involved because of the differential equations, but closed-form variants like CfC make this manageable with standard deep learning frameworks.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- Liquid Time-Constant Networks (LTCs) - https://github.com/raminmh/liquid_time_constant_networks
- PyTorch and TensorFlow implementation of NCP, LTC, and CfC models - https://github.com/mlech26l/ncps
- Liquid Neural Networks: The Future of Adaptable AI - https://em360tech.com/tech-articles/liquid-neural-networks-adaptable-ai
- Liquid Neural Networks & Edge‑Optimized Foundation Models: Sustainable On-Device AI for the Future - https://ajithp.com/2025/05/04/liquid-neural-networks-edge-ai/
- A novel uncertainty-aware liquid neural network for noise-resilient time series forecasting and classification - https://www.sciencedirect.com/science/article/abs/pii/S0960077925001432