How to Use AI as a Worldbuilding Partner for Your Fantasy Novel
Turn AI into a reliable worldbuilding partner for your fantasy novel with a world bible system, prompt templates, and tools that keep your lore consistent.
AIWorldbuildingFantasy Novel

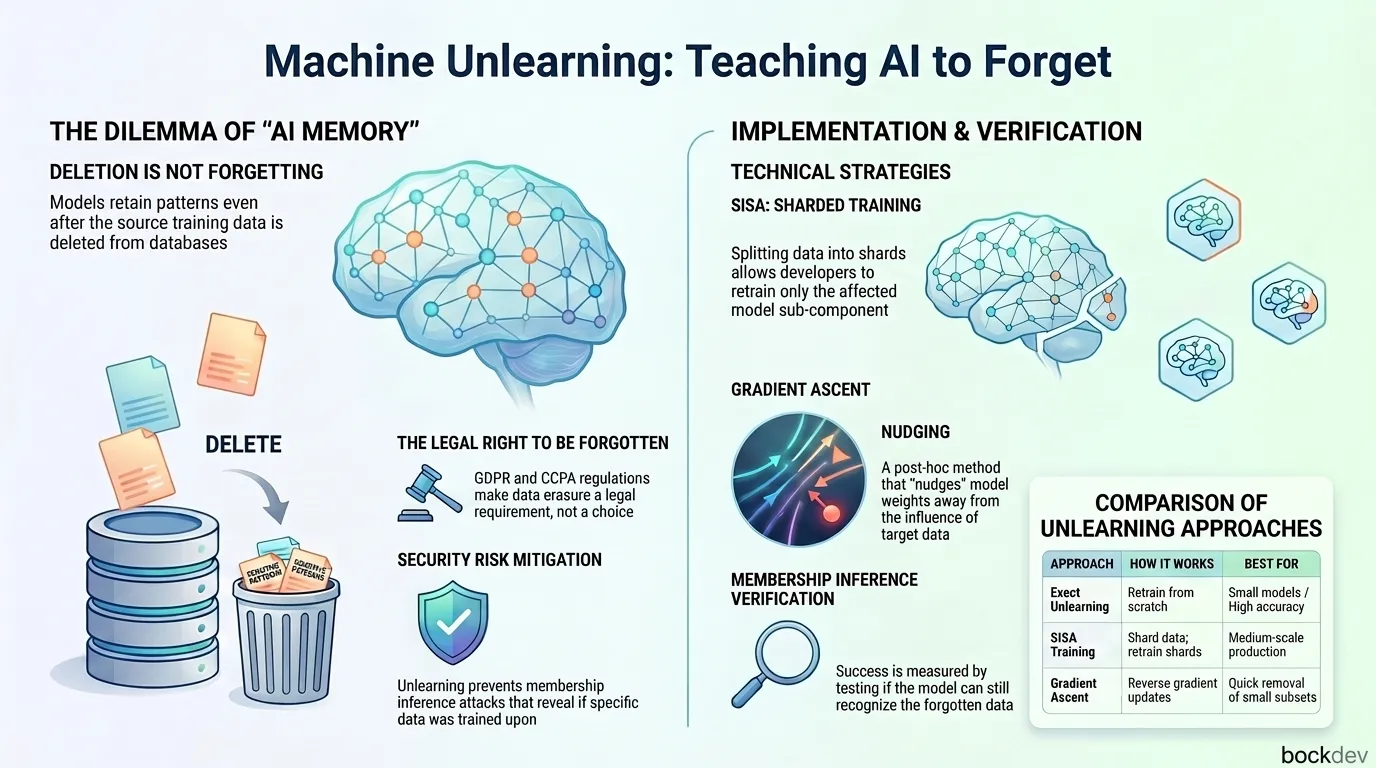
Machine unlearning is the process of removing specific data from a trained AI model without retraining it from scratch. This guide explains how it works, why it matters for privacy and compliance, and how developers can implement it today.
You trained an AI model on millions of data points. It performs beautifully. Then one day, a user says: "I never gave permission to use my data. Remove it."
What do you do? You cannot simply delete the record from your database and call it done. (If you were using Retrieval-Augmented Generation (RAG) to query data dynamically at runtime, a database deletion would suffice, but for a trained model, the patterns are already baked in). There is no obvious "undo" button.
This is the problem machine unlearning was built to solve. It is one of the most important and underappreciated topics in modern AI development, and with regulations like GDPR and CCPA, it is quickly becoming a legal requirement, not just a nice-to-have.
Machine unlearning is the process of making a trained model behave as if it never saw a specific piece of data, without retraining the entire model from scratch.
Think of it like this: if a model learned from 10 million records and one of those records needs to be removed, you do not want to spend days or weeks retraining from zero. Machine unlearning finds smarter ways to achieve the same result, faster and cheaper.
The concept is simple. The implementation is not.
There are three main reasons machine unlearning is becoming critical:
Privacy regulations: Laws like GDPR (EU) and CCPA (California) give users the "right to be forgotten." If your model trained on user data, you may be legally required to remove that influence.
Model correction: If a model learned from biased, toxic, or incorrect data, which is a growing risk with synthetic data and model collapse, you need a way to undo that damage without rebuilding the whole system from scratch. This is also relevant for addressing safety concerns, such as when models exhibit reward hacking or alignment faking.
Security: Membership inference attacks can reveal whether a specific record was in the training set. Unlearning can reduce that risk.
The obvious fix is to just retrain the model without the data in question.
This works perfectly, but it is almost always impractical. Training large models takes enormous time and compute. If you have to do it every time a user opts out, costs explode and workflows break.
That is why researchers have developed more efficient unlearning techniques.
| Approach | How It Works | Best For |
|---|---|---|
| Exact Unlearning | Retrain from scratch without the target data | Small models or offline systems |
| Data Partitioning (SISA) | Shard training data; retrain only affected shards | Medium-scale systems |
| Gradient Ascent | Push the model to "unlearn" by reversing gradient updates | Quick removal of small data subsets |
| Influence Functions | Estimate and subtract the data point's effect on model weights | Research and approximate unlearning |
| Model Fine-tuning | Fine-tune on the remaining data to overwrite old learning | Language models and fine-tuned systems |
Each approach has tradeoffs between accuracy, speed, and how completely the data is removed.
SISA (Sharded, Isolated, Sliced, and Aggregated) training is one of the most practical approaches for real-world use.
The idea is to split your training data into shards before training. Each shard trains a separate sub-model. When you need to unlearn a specific data point, you only retrain the shard that contained it, then re-aggregate the sub-models.
Here is a simplified example of how you might structure this:
import numpy as np
from sklearn.linear_model import LogisticRegression
# Step 1: Split training data into shards
def create_shards(X, y, num_shards=5):
indices = np.arange(len(X))
np.random.shuffle(indices)
shards = np.array_split(indices, num_shards)
return shards
# Step 2: Train a model per shard
def train_shard_models(X, y, shards):
models = []
for shard_idx in shards:
model = LogisticRegression()
model.fit(X[shard_idx], y[shard_idx])
models.append(model)
return models
# Step 3: Unlearn by retraining only the affected shard
def unlearn(X, y, shards, models, forget_index):
# Find which shard contains the data point to forget
for i, shard in enumerate(shards):
if forget_index in shard:
# Remove the data point from the shard
new_shard = shard[shard != forget_index]
shards[i] = new_shard
# Retrain only this shard
models[i] = LogisticRegression()
if len(new_shard) > 0:
models[i].fit(X[new_shard], y[new_shard])
break
return shards, models
# Step 4: Aggregate predictions across all shard models
def predict(models, X_test):
predictions = np.array([m.predict(X_test) for m in models])
# Majority vote
return np.apply_along_axis(
lambda x: np.bincount(x).argmax(), axis=0, arr=predictions
)This way, retraining cost is proportional to one shard, not the whole dataset.
If SISA was not used during training, gradient ascent is a common post-hoc approach. Instead of minimizing loss on the data you want to forget, you maximize it. This nudges the model weights away from that data's influence.
import torch
import torch.nn as nn
def gradient_ascent_unlearn(model, forget_loader, optimizer, steps=100):
model.train()
criterion = nn.CrossEntropyLoss()
for step in range(steps):
for inputs, labels in forget_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
# Ascend the loss instead of descending
(-loss).backward()
optimizer.step()
return modelAfter this, you typically fine-tune the model on the remaining data to restore performance on data you want to keep.
You cannot just assume the unlearning worked. You need to verify it.
The most common verification method is a membership inference attack. The idea is to test whether the model can still "recognize" the forgotten data as training data. If it cannot distinguish it from unseen data, the unlearning was successful.
from sklearn.metrics import roc_auc_score
def membership_inference_test(model, forget_data, test_data):
"""
A simplified membership inference check.
Returns AUC close to 0.5 if unlearning was successful.
"""
forget_confidences = get_confidence_scores(model, forget_data)
test_confidences = get_confidence_scores(model, test_data)
labels = [1] * len(forget_confidences) + [0] * len(test_confidences)
scores = forget_confidences + test_confidences
auc = roc_auc_score(labels, scores)
print(f"Membership Inference AUC: {auc:.3f}")
print("Close to 0.5 = successful unlearning")
return auc
def get_confidence_scores(model, data):
model.eval()
scores = []
with torch.no_grad():
for inputs, _ in data:
outputs = torch.softmax(model(inputs), dim=1)
scores.extend(outputs.max(dim=1).values.tolist())
return scoresA score near 0.5 means the model treats forgotten data like any unseen sample. That is your target.
Large language models present a unique challenge. Unlike smaller models highlighted in the small-model renaissance, you cannot easily shard training for GPT-scale models. Fine-tuning is usually the most practical option.
The typical workflow looks like this:
def llm_unlearn_step(model, forget_batch, retain_batch, optimizer, alpha=0.5):
model.train()
optimizer.zero_grad()
# Loss on forget set: maximize (gradient ascent)
forget_outputs = model(**forget_batch)
forget_loss = forget_outputs.loss
# Loss on retain set: minimize (standard training)
retain_outputs = model(**retain_batch)
retain_loss = retain_outputs.loss
# Combined objective
total_loss = -alpha * forget_loss + (1 - alpha) * retain_loss
total_loss.backward()
optimizer.step()
return forget_loss.item(), retain_loss.item()This is still an active research area. No method is perfect, but this approach gives a practical starting point.
If you are building an unlearning system, here is a clean way to organize it:
unlearning-pipeline/
├── data/
│ ├── shards/ # Pre-split training shards (for SISA)
│ ├── forget_set/ # Data marked for removal
│ └── retain_set/ # Remaining training data
├── models/
│ ├── shard_models/ # Per-shard trained models
│ └── final_model/ # Aggregated or fine-tuned model
├── src/
│ ├── shard_training.py # SISA training logic
│ ├── gradient_ascent.py # Post-hoc unlearning
│ ├── verification.py # Membership inference tests
│ └── llm_unlearn.py # LLM-specific fine-tuning
├── notebooks/
│ └── unlearning_demo.ipynb
├── requirements.txt
└── README.mdMachine unlearning is not solved. Here are the real obstacles:
Incomplete removal: Most approximate methods do not guarantee 100% removal. Traces may remain in model weights.
Performance degradation: Aggressive unlearning can hurt model accuracy on data you want to keep.
No universal benchmark: There is no agreed standard for proving a model has "forgotten" something. Verification methods vary widely.
Cost at scale: Even approximate unlearning on very large models can be expensive and slow.
Regulatory ambiguity: Laws like GDPR do not specifically define what "machine unlearning" must achieve technically. Legal standards are still evolving.
1. Is machine unlearning the same as deleting training data?
No. Deleting the raw data from storage does not remove what the model already learned. Machine unlearning modifies the model itself so that it behaves as if the data was never there.
2. Does retraining from scratch count as machine unlearning?
Yes, it is called exact unlearning. It is perfectly accurate but expensive. Most machine unlearning research focuses on cheaper alternatives.
3. Can machine unlearning fully erase a data point's influence?
Exact unlearning can. Approximate methods (like gradient ascent or fine-tuning) reduce but may not completely eliminate the influence. The gap between the two is still an open research problem.
4. Is machine unlearning required by GDPR?
GDPR grants users the "right to erasure," but it does not define the technical implementation. Whether retraining or approximate unlearning satisfies the law is a legal question that depends on the jurisdiction and the use case.
5. How do I know if my unlearning worked?
Use membership inference attacks to test whether the model still recognizes the forgotten data as training data. An AUC score near 0.5 is a good sign of successful unlearning.
6. Which method should I use for a production system?
If you can plan ahead, use SISA training. It gives the best balance of cost and effectiveness. If you have an already-trained model, gradient ascent or fine-tuning are your practical options.
7. Can machine unlearning be applied to LLMs like GPT or LLaMA?
Yes, but it is harder. Fine-tuning with a combined forget/retain objective is currently the most accessible approach. Research into scalable LLM unlearning is ongoing.
8. What is a forget set vs a retain set?
The forget set is the data you want the model to stop knowing. The retain set is all the data you want the model to keep performing well on. Good unlearning degrades performance on the forget set without hurting the retain set.
9. Can adversaries reverse machine unlearning?
This is an active area of concern. Some research shows that model weight analysis might reveal traces of forgotten data, especially with approximate methods. This is why verification and ongoing auditing matter.
10. Are there open-source tools for machine unlearning?
Yes. Libraries like machine-unlearning (Python), research repos from NeurIPS unlearning challenges, and tools built on top of Hugging Face Transformers are available. The field is young, so tooling is still maturing.
Bourtoule, L., et al. (2021). Machine Unlearning - https://arxiv.org/abs/1912.03817
Sekhari, A., et al. (2021). Remember What You Want to Forget: Algorithms for Machine Unlearning - https://arxiv.org/abs/2103.03279
Nguyen, T. T., et al. (2022). A Survey of Machine Unlearning - https://arxiv.org/abs/2209.02299
Cao, Y., & Yang, J. (2015). Towards Making Systems Forget with Machine Unlearning - https://ieeexplore.ieee.org/document/7163042
Tags
Turn AI into a reliable worldbuilding partner for your fantasy novel with a world bible system, prompt templates, and tools that keep your lore consistent.
How writers use AI as a brainstorming partner for characters, worldbuilding, and writer's block, without letting it write the story for you.

AI hallucinations happen when models generate confident but false answers. Here's why it occurs and how to spot and reduce it.

A 7-minute routine to find and limit how AI tools and platforms collect, store, and train on your personal data.

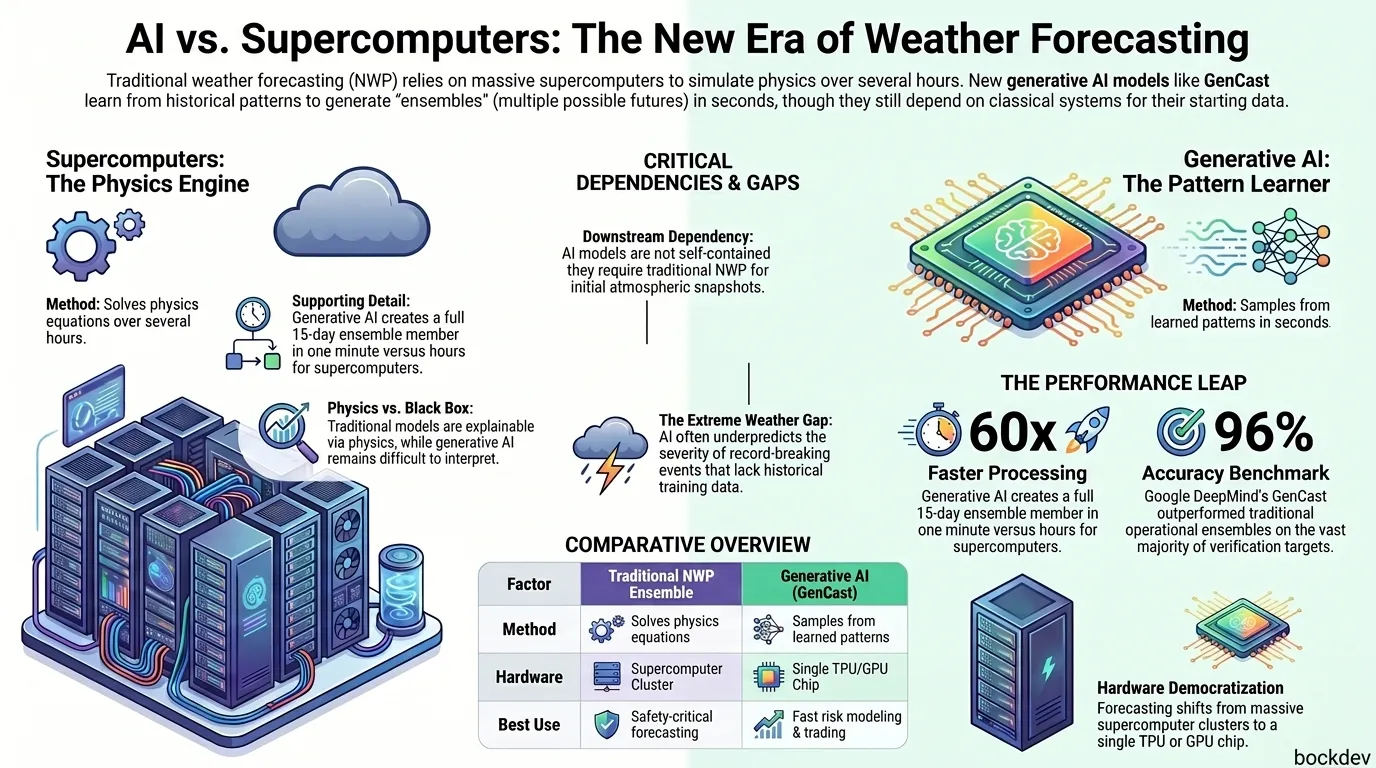
Generative AI models like GenCast now create weather ensembles in minutes instead of hours, changing how forecasts are built and used.