Appearance

What Is RAG? A Beginner's Guide to Retrieval-Augmented Generation
Learn how RAG works, its core components (vector databases, retriever, LLM), and compare it to fine-tuning.

Retrieval-Augmented Generation (RAG) is an AI framework that improves the accuracy and reliability of Large Language Models (LLMs) by fetching relevant facts from external sources before generating a response. By anchoring prompts to real-time external data, RAG reduces hallucinations and enables models to answer queries with up-to-date information.
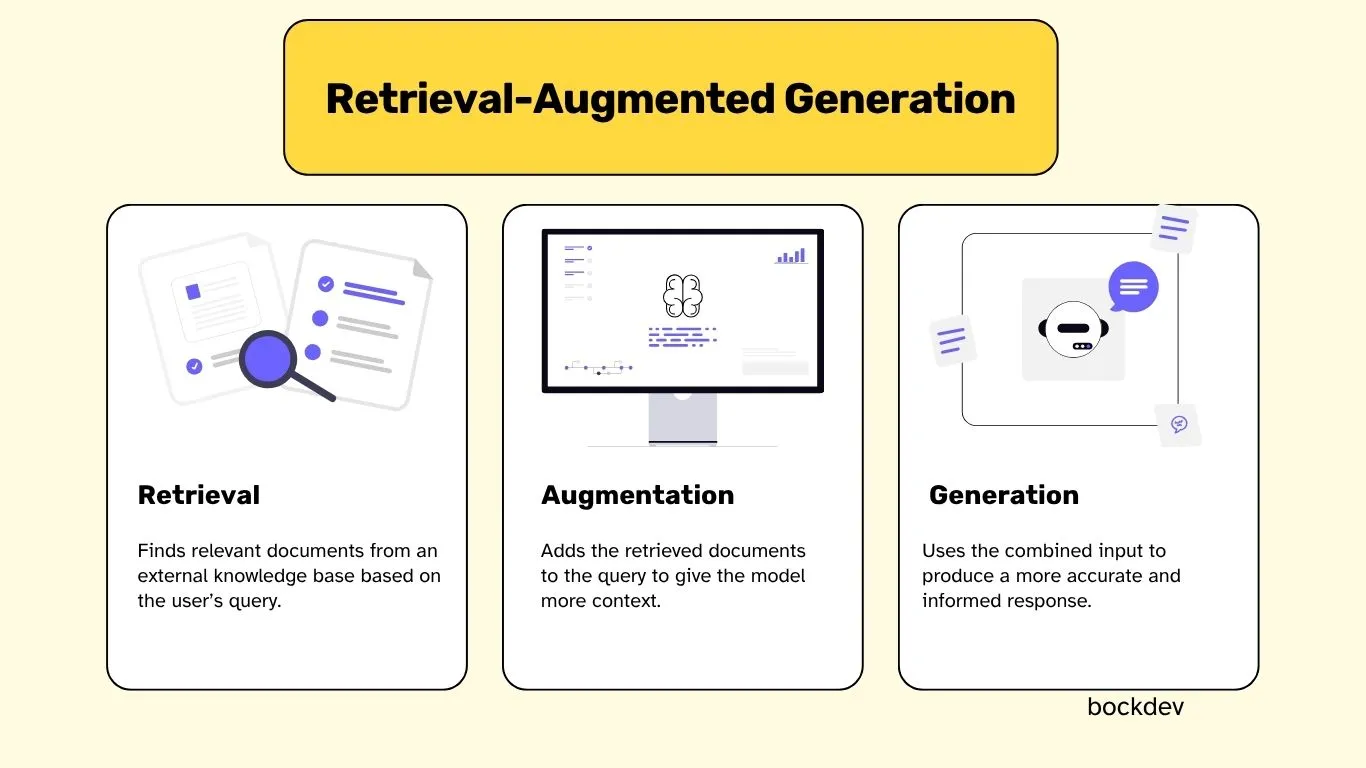
RAG can be explained by breaking it down into three core concepts:
Retrieval: Finds relevant documents from an external knowledge base based on the user’s query.
Augmented: Adds the retrieved documents to the query to give the model more context.
Generation: Uses the combined input to produce a more accurate and informed response.
Core concepts of RAG.
Core Components of a RAG Architecture
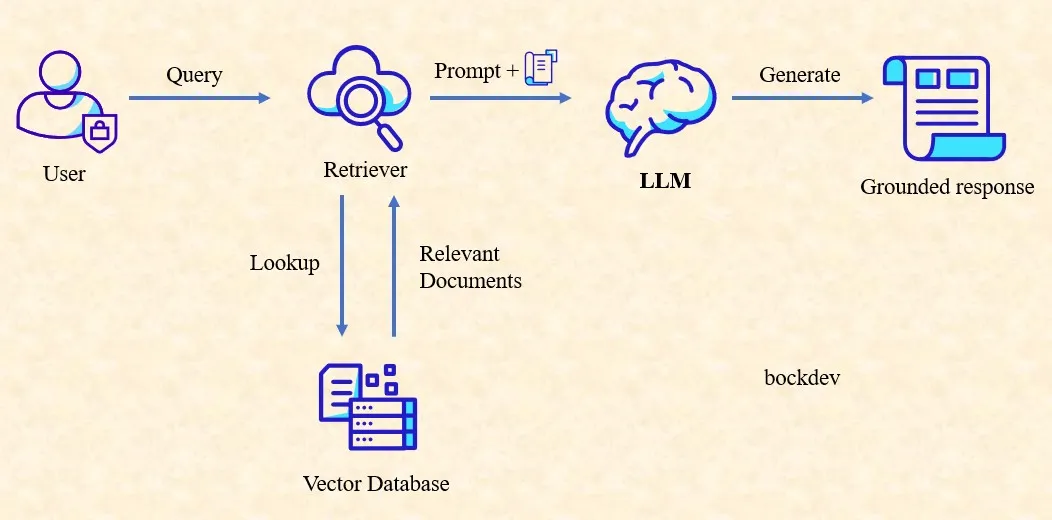
1. Retriever
This component searches a knowledge base (usually stored in a vector database) for relevant documents based on the user's query. It uses embedding models to convert text into vectors and retrieve semantically similar content.
2. Knowledge Base / Vector Store
A database that holds the pre-processed and embedded documents. Common tools include FAISS, Pinecone, or Weaviate. It enables fast and meaningful search based on vector similarity rather than keyword matching.
3. Prompt Constructor / Augmenter
This module combines the user query and the retrieved documents into a structured prompt for the language model. It often includes instructions to guide the model to answer only based on the provided context.
4. Generator (LLM)
Generator (LLM) receives the augmented prompt and generates a natural language response. It uses both the user query and the retrieved context to produce accurate, grounded answers.
RAG Process Overview.
How Retrieval-Augmented Generation Works (Step-by-Step)
1. Preparing External Knowledge Sources
The first step involves collecting useful content such as internal documents, articles, and help guides. These materials are split into smaller chunks to make them easier to manage and retrieve. Each chunk is processed by an embedding model, which converts the text into numerical vectors representing their meaning. These vectors are then stored in a vector database, forming the foundation of a searchable external knowledge base for later use.
2. Retrieving Contextual Information
When a user submits a query, the system embeds the query into a vector using the same model used for the documents. It then searches the vector database to find chunks with similar meanings. These retrieved pieces of text are considered the most relevant to the question. This allows the system to find helpful, targeted information dynamically without relying solely on the language model’s internal and potentially outdated training data.
3. Building a Contextual Prompt for the LLM
After retrieving relevant document chunks, the system constructs a prompt for the language model. This prompt includes the user's original question and the retrieved content, along with optional instructions to ensure the model stays focused. By combining external context with the query, the language model is able to generate answers that are more accurate, grounded in real information, and less prone to hallucinations or generic responses.
4. Maintaining and Updating Knowledge Sources
One major benefit of RAG is the ability to update knowledge without re-training the model. When new documents are added or existing ones change, they are simply reprocessed into embeddings and stored in the vector database. This makes it easy to keep the system current. Any updates are immediately reflected in future responses, making RAG highly maintainable and suitable for domains where information changes frequently.
Key Benefits of Using RAG for LLMs
RAG is used to overcome key limitations of language models and improve their performance in real-world applications. Here's why it's valuable:
1. Access to Up-to-Date Information
LLMs are trained on static datasets and can become outdated. RAG connects them to external, current sources, allowing responses to reflect the latest knowledge without re-training the model.
2. Reduced Hallucination
By grounding answers in real documents retrieved from a vector database, RAG minimizes the chances of the model generating incorrect or fabricated facts.
3. Domain Adaptability
RAG makes it easy to adapt a general-purpose model to specific domains (e.g., legal, medical, internal company data) by simply uploading relevant documents, bypassing the need for training domain-specific models.
4. Cost and Time Efficiency
Fine-tuning large models can be expensive and time-consuming. RAG enables real-time knowledge updates without re-training, reducing operational overhead.
5. Improved Transparency
RAG returns the source documents used to generate answers, users can see where the information comes from to boost trust and interpretability.
8 Main Challenges of Implementing RAG
Here are some key current and future challenges of RAG:
Retrieval Quality - Poor retrieval leads to irrelevant or misleading context, which harms answer quality. Ensuring high recall and precision in dense search remains a core challenge.
Prompt Length Limits - LLMs have token limits. Including too many retrieved documents can overflow the prompt, while too few may miss critical context. Balancing relevance and length is tricky, and can lead to issues like context drift.
Data Freshness & Sync - Keeping the knowledge base updated in real time, especially from fast-changing sources (e.g., news, customer support logs), is challenging.
Evaluation Metrics - It's hard to measure how much RAG improves performance. Traditional metrics (e.g., BLEU, ROUGE) may not fully reflect helpfulness or factual accuracy in a RAG pipeline.
Latency and Cost - RAG adds overhead: embedding, vector search, reranking, and prompt construction. This can increase inference time and operational costs, especially at scale.
Handling Contradictions or Noise - Retrieved documents may contain conflicting or outdated information. LLMs might mix sources or fail to resolve inconsistencies.
Security and Privacy - If the knowledge base contains sensitive or proprietary data, there are risks of unintentional leakage in generated responses.
Hallucination Still Happens - Even with relevant context, LLMs may still hallucinate. RAG reduces this risk but doesn’t eliminate it.
Real-World Examples of RAG Applications
Customer Support Assistant
Scenario: A user asks, “How do I reset my password?”
Action: RAG retrieves relevant FAQ or internal helpdesk docs, adds them to the prompt, and the LLM generates a clear step-by-step guide customized to the user’s product.
Legal Document Search
Scenario: A lawyer asks, “What are the clauses related to liability in this contract?”
Action: RAG fetches relevant sections from the uploaded contract using semantic search, augments the prompt, and the model explains the liability clauses in plain English.
Codebase Question Answering
Scenario: A developer asks, “Where is the login logic implemented in this project?”
Action: RAG searches the code repository (with embeddings) for related functions or files, adds them to the prompt, and the LLM summarizes or points to the implementation (read more on codebase navigation tools in A Practical Overview of MCP).
Research Assistant for Healthcare
Scenario: A researcher asks, “What are the latest treatments for type 2 diabetes?”
Action: RAG retrieves relevant excerpts from medical journals or databases, feeds them into the LLM, and produces a well-cited, up-to-date summary of treatment options.
Internal Company Knowledge Tool
Scenario: An employee asks, “How do I apply for reimbursement in our new expense system?”
Action: RAG pulls the latest policy documents and guidance from internal Wikis or PDFs, augments the prompt, and returns a user-friendly answer with links or steps.
RAG vs. Fine-Tuning vs. Prompt Engineering vs. Pre-Training
1. Retrieval-Augmented Generation (RAG)
RAG enriches language models by retrieving relevant documents from an external source like a vector database and feeding that content into the model's prompt. This makes the model "smarter" in real time without re-training.
Pros
- Accesses up-to-date or large external knowledge.
- Reduces hallucinations by grounding responses in real documents.
Cons
- Slower due to retrieval step.
- Requires infrastructure like a vector database.
2. Pre-training
Pre-training is the process of teaching a model language from scratch by exposing it to a vast amount of raw text. This builds the foundational knowledge and reasoning abilities of the model.
Pros
- Full control over training data.
- Tailored to your specific goals and ethics.
Cons
- Extremely expensive and time-consuming.
- Requires huge datasets and compute resources.
3. Prompt Engineering
Prompt engineering is the art of crafting the right input to get the desired behavior from an LLM. It includes techniques like few-shot, zero-shot, and chain-of-thought prompting.
Pros
- Fast and inexpensive to apply.
- No training or infrastructure required.
Cons
- Prompt effectiveness can be unpredictable.
- Doesn’t scale well to very specific or complex tasks.
4. Fine-tuning
Fine-tuning adjusts a pre-trained model’s weights using a domain-specific or task-specific dataset. The model "learns" from examples and becomes better at that specific job.
Pros
- High performance on targeted tasks.
- Can embed domain knowledge directly into the model.
Cons
- Updating content requires re-training.
- Can overfit or forget general knowledge.
RAG vs. Other Methods: Which is Most Effective?
If your data changes often or is too large to fit in a prompt, then use RAG.
If you're building a model from scratch with large-scale data and resources, then use pre-training.
If you're prototyping or need quick customization without touching the model weights, then use prompt engineering.
If you have a stable dataset and want a domain-specific model that performs consistently, then use fine-tuning.
Comparison Table: RAG, Fine-Tuning, and Prompt Engineering
| Method | Cost | Customization | Best For |
|---|---|---|---|
| RAG | Medium | High | Dynamic data, explainability |
| Pre-training | Very High | Very High | Foundational models |
| Prompt Engineering | Low | Medium | Prototyping, general use |
| Fine-Tuning | High | High | Narrow, high-accuracy tasks |
Conclusion
RAG offers a powerful way to enhance LLMs by combining real-time data retrieval with generation. It enables more accurate, up-to-date, and grounded responses, making it ideal for dynamic domains where traditional fine-tuning or static prompts fall short.