How to Use AI as a Worldbuilding Partner for Your Fantasy Novel
Turn AI into a reliable worldbuilding partner for your fantasy novel with a world bible system, prompt templates, and tools that keep your lore consistent.
AIWorldbuildingFantasy Novel

Learn what test-time compute means, how it differs from traditional AI training, and why this shift from memorizing to reasoning is changing the way large language models solve hard problems.
You ask an AI a tricky math problem. It spits out an answer in seconds. Sounds impressive, right? But here is the catch: it might just be recalling a pattern it saw during training, not actually solving the problem. And when the pattern does not fit perfectly, it fails.
This is the core weakness of how most AI models have worked until recently. They are trained on massive datasets, compress all that knowledge into their weights, and then retrieve it at lightning speed. Fast? Yes. Flexible? Not always.
The good news is that a new approach is changing this. It is called test-time compute, and it is shifting AI from pure memorization toward genuine reasoning. This post breaks down what that means, why it matters, and how it actually works.
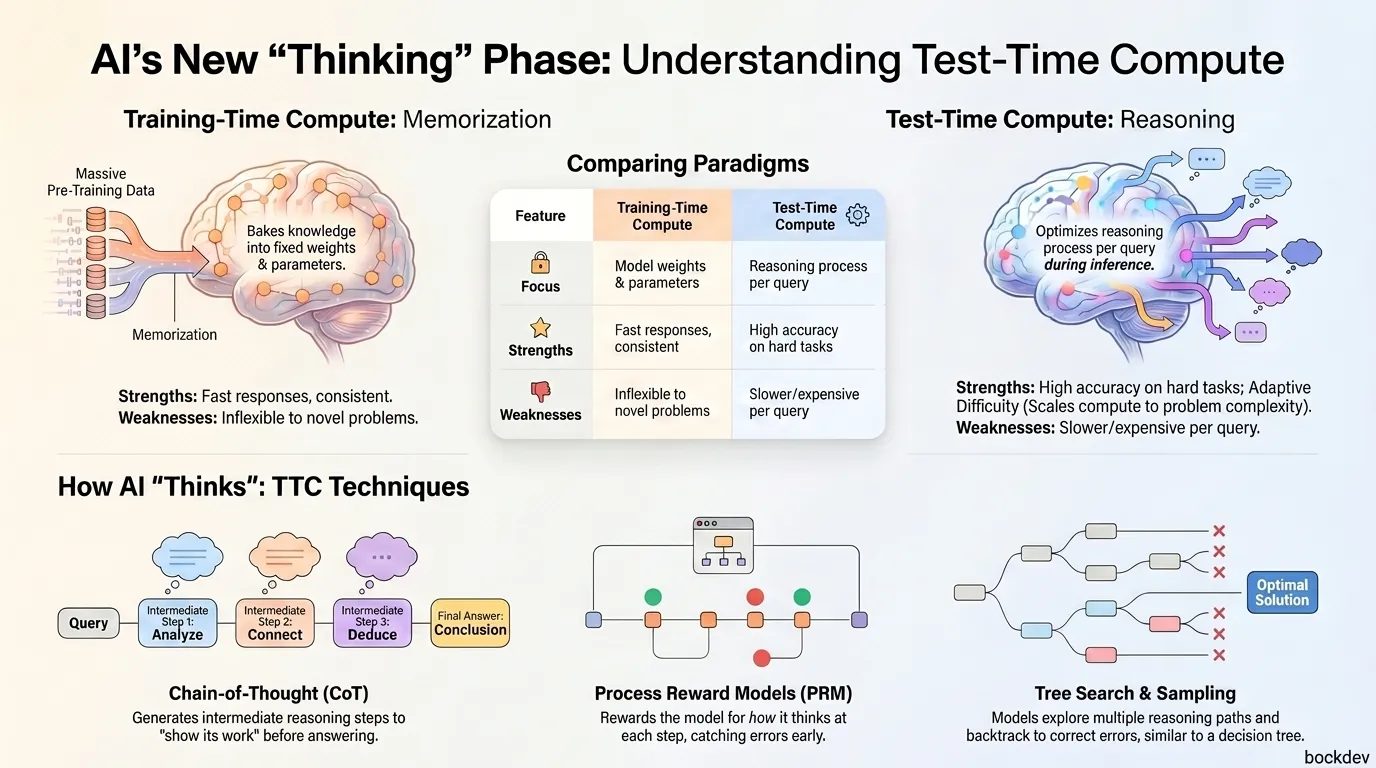
Test-time compute (TTC) refers to the computational work an AI model does after training, at the moment it is answering your question.
Most AI research has focused on scaling training: bigger models, more data, more GPU hours. Test-time compute flips the focus. Instead of trying to bake all intelligence into the model's weights during training, TTC lets the model "think longer" when it encounters a hard problem at runtime.
Think of it like this: a student who memorized answers can only do well on questions they have seen before. A student who knows how to think through problems can tackle new ones. TTC is teaching AI to be the second kind of student.
Here is a side-by-side comparison:
| Feature | Training-Time Compute | Test-Time Compute |
|---|---|---|
| When it happens | Before deployment | During inference |
| What it optimizes | Model weights and parameters | The reasoning process per query |
| Cost driver | GPU hours for training runs | Compute per user request |
| Strengths | Fast responses, consistent output | Better accuracy on hard tasks |
| Weaknesses | Inflexible to novel problems | Slower and more expensive per query |
| Example | GPT-3 style pretraining | OpenAI o1, DeepSeek-R1 |
Both approaches are not mutually exclusive. Modern systems often use both: a well-trained model that can also reason at inference time.
There are several techniques that give AI models more "thinking time" at inference:
Instead of jumping straight to an answer, the model generates intermediate reasoning steps.
User: What is 17 x 24?
Model (with CoT):
Step 1: Break it down. 17 x 24 = 17 x 20 + 17 x 4
Step 2: 17 x 20 = 340
Step 3: 17 x 4 = 68
Step 4: 340 + 68 = 408
Answer: 408This forces the model to "show its work," which dramatically improves accuracy on multi-step problems.
The model generates multiple answers using different reasoning paths, then selects the most common result.
# Pseudocode: self-consistency with majority voting
responses = []
for i in range(10):
response = model.generate(prompt, temperature=0.8)
responses.append(extract_answer(response))
final_answer = majority_vote(responses)This is powerful because wrong answers tend to be random, while correct answers tend to cluster.
Generate N candidate responses and score each one using a reward model, then return the best.
candidates = [model.generate(prompt) for _ in range(N)]
scores = [reward_model.score(c) for c in candidates]
best = candidates[scores.index(max(scores))]The key here is having a reliable reward model that knows what "good" looks like.
The model explores multiple reasoning paths like a decision tree, evaluating partial solutions before committing to a full answer.
Question: Solve a complex logic puzzle
[Start]
/ \
[Path A] [Path B]
/ \ \
[A1] [A2] [B1]
(dead end) (promising) (dead end)
|
[Final Answer]This is computationally expensive but allows the model to backtrack and correct itself.
A key design choice in TTC systems is where you apply the reward signal:
| Type | When it rewards | Advantage |
|---|---|---|
| Outcome Reward Model (ORM) | Only at the final answer | Simple to train |
| Process Reward Model (PRM) | At each reasoning step | Catches errors early, better for complex tasks |
PRMs are harder to build because you need step-level annotations. But they produce much better reasoning behavior because they reward how the model thinks, not just what it concludes.
The old assumption was: if you want a smarter AI, train a bigger model on more data. That is increasingly expensive and hitting diminishing returns.
Test-time compute proposes a different trade-off. You can use a smaller, cheaper model and give it more compute at inference when the problem is hard. This is more efficient for complex tasks where raw memorization fails.
It also unlocks something new: adaptive difficulty. Easy questions get fast, cheap answers. Hard questions get more thinking time. The compute scales to the problem, not to a fixed model size.
This mirrors how humans work. You do not spend 10 minutes thinking about what 2+2 equals. But you might spend an hour working through a complex planning decision.
Several production AI systems now use TTC techniques:
OpenAI o1 / o3 Uses extended chain-of-thought reasoning internally before producing a final answer. Users see the output, not the scratchpad.
DeepSeek-R1 An open-source model trained with reinforcement learning to improve reasoning step-by-step. Demonstrates that TTC benefits can be achieved without massive pretraining budgets.
Google Gemini 2.0 Flash Thinking Integrates multi-step reasoning with controlled compute budgets for different task difficulties.
AlphaCode 2 Uses repeated sampling and filtering to generate and evaluate thousands of code solutions before picking the best one.
More thinking means more tokens generated, which means more compute cost. This creates a real engineering challenge.
Simple query: 1x compute
Complex reasoning query: 10x-100x computeThe solution most teams are working on is a routing system:
def route_query(query):
difficulty = estimate_difficulty(query)
if difficulty == "easy":
return fast_model.generate(query)
elif difficulty == "medium":
return cot_model.generate(query)
else:
return reasoning_model.generate(query, budget=HIGH)This keeps costs manageable while unlocking the benefits of deeper reasoning when it actually matters.
TTC changes where researchers invest their effort. Instead of only asking "how do we make training better," they now also ask "how do we make inference smarter."
This opens up new directions:
It also raises a deeper question about what "intelligence" means in AI. Is it the size of what a model memorized, or the quality of how it reasons? TTC bets on the latter.
1. What does "test-time" mean exactly?
It refers to inference time, which is when you are actually using the model to answer a question, as opposed to training time when the model is being built.
2. Does test-time compute work for all types of tasks?
It helps most with tasks that require multi-step reasoning, like math, coding, and logic puzzles. For simple factual recall, it adds cost without much benefit.
3. Is chain-of-thought prompting always better?
Not always. For simple tasks, CoT can actually slow things down and occasionally introduce errors. It works best on complex problems with multiple steps.
4. How is a Process Reward Model trained?
It requires human (or AI-generated) annotations at each step of the reasoning chain, labeling which steps are correct or helpful. This is more labor-intensive than training an outcome-based reward model.
5. Does this mean smaller models can match larger ones?
In some tasks, yes. A smaller model with extended reasoning time can outperform a larger model on complex problems. But this is not universal: the base model still needs to be capable enough to reason at all.
6. What is the risk of self-consistency sampling?
If the model is systematically wrong in the same way across multiple samples, majority voting will reinforce the wrong answer. It works well when errors are random, not systematic.
7. How do models know when to "think harder"?
Current systems often use a fixed budget or are prompted to reason step-by-step. Research is ongoing into adaptive compute allocation that automatically detects problem difficulty.
8. Is test-time compute related to reinforcement learning?
Yes. Many TTC systems use reinforcement learning to train the model to generate better reasoning steps. DeepSeek-R1 is a prominent example of RL-trained reasoning.
9. Can test-time compute lead to hallucinations?
Longer reasoning chains can sometimes introduce more opportunities for errors to compound. Good process reward models help reduce this by penalizing incorrect intermediate steps.
10. What is the biggest open challenge in test-time compute?
Building reliable reward models that can accurately judge the quality of reasoning steps, especially in domains where correct answers are hard to verify automatically.
Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - https://arxiv.org/abs/2201.11903
Lightman, H. et al. (2023). Let's Verify Step by Step - https://arxiv.org/abs/2305.20050
Guo, D. et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning - https://arxiv.org/abs/2501.12948
Snell, C. et al. (2024). Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Model Parameters - https://arxiv.org/abs/2408.03314
Brown, B. et al. (2024). Large Language Monkeys: Scaling Inference Compute with Repeated Sampling - https://arxiv.org/abs/2407.21787
Tags
Turn AI into a reliable worldbuilding partner for your fantasy novel with a world bible system, prompt templates, and tools that keep your lore consistent.
How writers use AI as a brainstorming partner for characters, worldbuilding, and writer's block, without letting it write the story for you.

AI hallucinations happen when models generate confident but false answers. Here's why it occurs and how to spot and reduce it.

A 7-minute routine to find and limit how AI tools and platforms collect, store, and train on your personal data.

Generative AI models like GenCast now create weather ensembles in minutes instead of hours, changing how forecasts are built and used.