Appearance

Generalist Giants vs. DSLMs: Which AI Model Should You Actually Use?
A clear comparison of Domain-Specific Language Models (DSLMs) and generalist LLMs, covering accuracy, cost, compliance, and how to choose or build the right one for your use case.
Your team adopted ChatGPT or Claude for everything from drafting emails to answering customer questions. It worked great at first. Then someone asked it a question about your internal pricing rules, a regulatory edge case, or a piece of medical terminology, and the answer came back confident, fluent, and wrong.
This is not a "bad AI" problem. It is a fit problem. General-purpose models are trained to know a little about everything. They were never built to know everything about one thing, like your industry's jargon, compliance rules, or proprietary data.
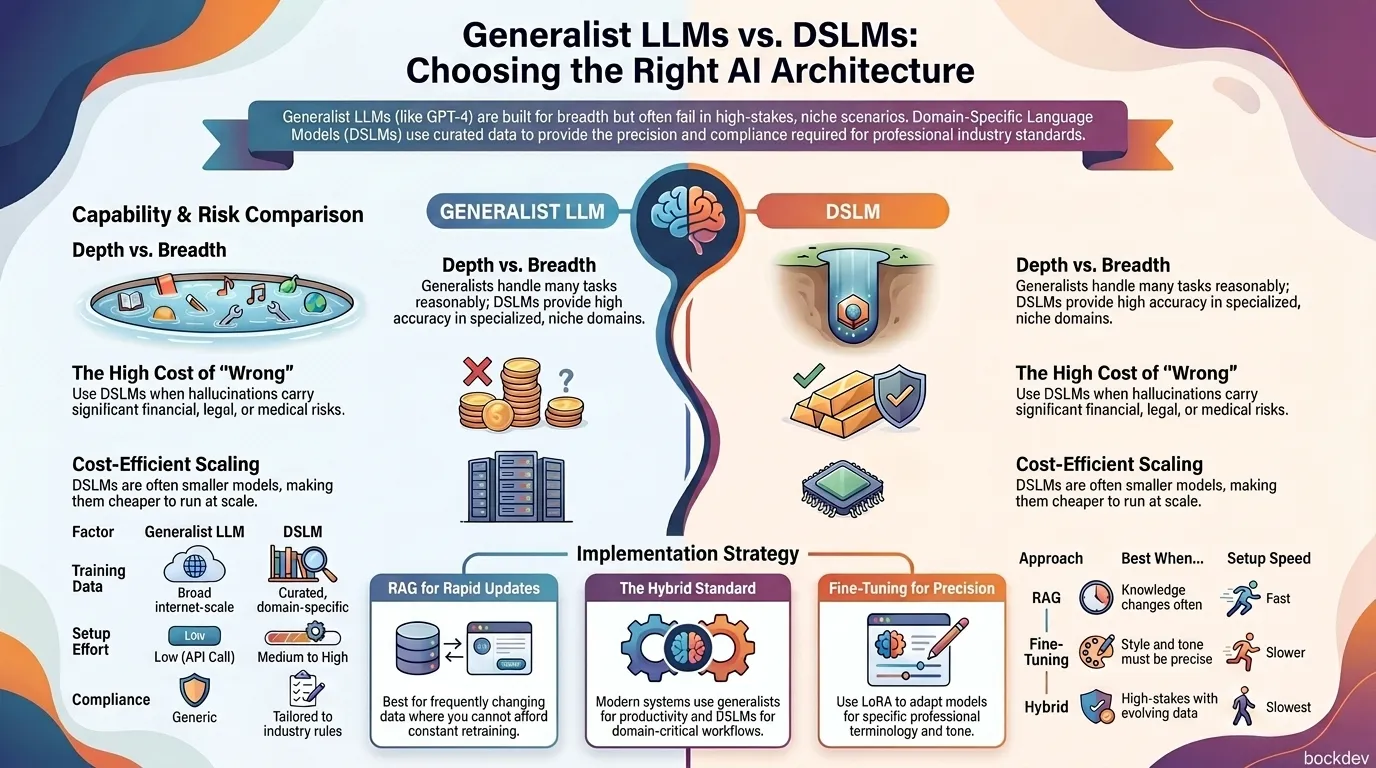
That is exactly the gap Domain-Specific Language Models (DSLMs) are built to close. This post breaks down what DSLMs actually are, how they differ from generalist models like GPT or Claude, and how to decide (or build) the right one for your use case, without the marketing fluff.
What Is a Generalist LLM?
A generalist LLM (GPT-4, Claude, Gemini, etc.) is trained on huge, broad datasets: websites, books, code, forums, academic papers.
It is built for breadth, not depth. One model can draft a marketing email, debug Python, and summarize a contract in the same conversation.
Strengths:
- Fast to deploy via API, no training needed
- Handles many tasks reasonably well
- Constantly improving with frontier-level reasoning
Weaknesses:
- Shallow on niche or regulated domains
- No built-in knowledge of your private data
- Can "hallucinate" confidently on specialized topics
What Is a DSLM?
A Domain-Specific Language Model is a model trained, fine-tuned, or augmented using data from one specific field, like law, medicine, finance, or manufacturing.
Instead of trying to know everything, it goes deep on one thing. Think of it as the difference between a general doctor and a specialist surgeon.
Strengths:
- Higher accuracy on domain-specific tasks
- Understands industry jargon and context out of the box
- Easier to align with compliance and regulatory needs
- Often smaller and cheaper to run at scale
Weaknesses:
- Limited outside its trained domain
- Requires good-quality domain data to build
- Needs more upfront engineering effort
DSLM vs Generalist LLM: Side-by-Side Comparison
| Factor | Generalist LLM | DSLM |
|---|---|---|
| Training data | Broad, internet-scale | Curated, domain-specific |
| Accuracy in niche tasks | Moderate | High |
| Setup effort | Low (API call) | Medium to high |
| Inference cost at scale | Higher (large model) | Often lower (smaller model) |
| Compliance fit | Generic | Tailored to industry rules |
| Flexibility across tasks | High | Low (narrow by design) |
| Best for | General productivity, broad Q&A | Regulated, high-precision workflows |
How Companies Actually Build a DSLM
Most teams do not train a model from scratch. They start with an open base model and adapt it. The most common, cost-efficient method is LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning technique that only trains a small set of extra weights instead of the whole model.
Here is a minimal example using Hugging Face's peft library:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
# 1. Load a base open model
model_id = "Qwen/Qwen2-7B"
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 2. Define the LoRA configuration
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # rank: lower = fewer trainable params
lora_alpha=32,
lora_dropout=0.05,
target_modules=["q_proj", "v_proj"], # apply LoRA to attention layers
bias="none",
)
# 3. Wrap the model with the adapter
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: ~0.2% of total model paramsThen fine-tune it on your domain dataset with SFTTrainer from trl:
python
from trl import SFTTrainer, SFTConfig
training_args = SFTConfig(
output_dir="./dslm-finance-adapter",
learning_rate=2e-4, # higher LR is typical for LoRA
num_train_epochs=3,
per_device_train_batch_size=4,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=domain_dataset, # your curated, domain-specific data
peft_config=lora_config,
)
trainer.train()
trainer.save_model("./dslm-finance-adapter")This saves only the small adapter weights (a few MB), not a full new model. You merge it with the base model later for deployment.
A Lighter Alternative: RAG Instead of Fine-Tuning
If you do not want to fine-tune at all, RAG (Retrieval-Augmented Generation) lets a generalist LLM "borrow" domain knowledge at query time by pulling relevant documents from your own database before answering.
A typical RAG project structure looks like this:
dslm-rag-project/
├── data/
│ ├── policy_docs/
│ └── product_manuals/
├── ingestion/
│ ├── chunk_documents.py
│ └── embed_and_store.py
├── retrieval/
│ └── query_vector_db.py
├── app/
│ └── chat_with_context.py
└── config.yamlA simplified retrieval call looks like this:
python
from sentence_transformers import SentenceTransformer
import chromadb
embedder = SentenceTransformer("all-MiniLM-L6-v2")
client = chromadb.PersistentClient(path="./vector_db")
collection = client.get_collection("domain_docs")
query = "What is our refund policy for enterprise clients?"
query_vector = embedder.encode(query).tolist()
results = collection.query(query_embeddings=[query_vector], n_results=3)
context = "\n".join(results["documents"][0])
prompt = f"Answer using only this context:\n{context}\n\nQuestion: {query}"
# Send `prompt` to your LLM of choice (GPT, Claude, open model, etc.)RAG is faster to set up than fine-tuning and works well when your domain knowledge changes often, since you just update the database instead of retraining.
Fine-Tuning vs RAG vs Hybrid: Quick Decision Guide
| Approach | Best when... | Setup speed | Update frequency |
|---|---|---|---|
| Generalist LLM only | Tasks are broad, low stakes | Fastest | N/A |
| RAG | Knowledge changes often, no GPU budget | Fast | Easy (update docs) |
| Fine-tuned DSLM | Accuracy and tone must be precise | Slower | Requires retraining |
| Hybrid (RAG + DSLM) | High-stakes domain with evolving data | Slowest | Moderate |
Most production systems in 2026 use a hybrid setup: a generalist model for everyday tasks, and a fine-tuned or RAG-backed DSLM for the domain-critical workflows.
When Should You Actually Use a DSLM?
Use a DSLM when:
- Wrong answers carry real cost (medical, legal, financial decisions)
- Your industry has strict compliance or audit requirements
- You have enough quality domain data to train or retrieve from
- You need consistent terminology and tone at scale
Stick with a generalist LLM when:
- Use cases are broad and low-risk (drafting, brainstorming, summarizing)
- You need to move fast without building infrastructure
- Your data volume is too small to fine-tune meaningfully
Q&A
1. Is a DSLM a completely different model architecture from a generalist LLM?
No. Most DSLMs use the same transformer architecture. The difference is in the training data and fine-tuning process, not the underlying design.
2. Do I need a huge dataset to build a DSLM?
Not necessarily. LoRA-style fine-tuning can produce solid results with a few thousand high-quality, domain-specific examples.
3. Is fine-tuning always better than RAG?
No. RAG is often better when your data changes frequently, since you avoid retraining. Fine-tuning is better when you need the model to "think" and respond in a specific style or format consistently.
4. Can I combine a DSLM with a generalist LLM?
Yes, this is the most common setup. The generalist model handles broad tasks, and the DSLM (or RAG pipeline) handles domain-critical queries.
5. Are DSLMs always cheaper to run?
Often, yes, since they can be built on smaller base models that are sufficient for a narrow task, but the upfront training and data curation cost is real.
6. Do DSLMs need to be retrained often?
Only when domain knowledge meaningfully changes, like new regulations. Minor updates can often be handled with RAG instead of full retraining.
7. What industries benefit most from DSLMs?
Healthcare, finance, law, manufacturing, and any other field with specialized terminology, regulatory pressure, or high accuracy requirements.
8. Can a small team realistically build a DSLM?
Yes. Tools like Hugging Face's peft and trl make LoRA fine-tuning accessible on a single GPU, without needing massive infrastructure.
9. Does using a DSLM mean giving up general capabilities?
Yes, to some degree. DSLMs are intentionally narrow. That is the trade-off for higher accuracy in their specific domain.
10. How do I know if my use case needs a DSLM at all?
Ask whether a wrong or generic answer would cause real harm or cost. If yes, a DSLM (or at least RAG) is worth the investment. If no, a generalist LLM is usually enough.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- Kerner, T. (2024). Domain-Specific Pretraining of Language Models: A Comparative Study in the Medical Field - https://arxiv.org/pdf/2407.14076
- Generic vs. Domain-Specific Large Language Models: A Business-Oriented Comparison - https://arya.ai/blog/generic-vs-domain-specific-llms
- Custom Llm Vs General Purpose Llm for Business - https://gaper.io/custom-llm-vs-general-purpose-llm/
- Hugging Face TRL Documentation, PEFT Integration Guide - https://huggingface.co/docs/trl/en/peft_integration
- Hugging Face PEFT Documentation, LoRA Conceptual Guide - https://huggingface.co/docs/peft/main/en/conceptual_guides/lora