Hyper-Personalized AI Content at Scale: How Brands Build 1:1 Experiences Without Creeping Out Users in 2026
Learn how brands in 2026 are using AI to deliver personalized content at scale, one-to-one user experiences, and privacy-first strategies that build trust instead of breaking it.
You open an email from a brand you barely remember signing up for. It mentions your job title, references something you browsed last week, and recommends a product that feels weirdly specific. Your first reaction is not "wow, helpful." It is "how do they know that?"
That is the line brands are walking right now. AI makes it possible to personalize content for every single user, at scale, automatically. But when it is done wrong, it does not feel helpful. It feels invasive. Users tune out, unsubscribe, or worse, lose trust in your brand completely.
The good news is that getting this right is not about pulling back on personalization. It is about doing it smarter, with the right signals, the right boundaries, and the right tech stack behind it.
What "Hyper-Personalization" Actually Means in 2026
Hyper-personalization is not just using someone's first name in an email. It means delivering the right content, in the right format, at the right moment, based on real behavioral signals rather than assumptions.
In 2026, this is powered by a combination of:
First-party data (what users share with you directly)
AI content generation (models that create or adapt content in real time)
Contextual triggers (time of day, device, location, stage in the funnel)
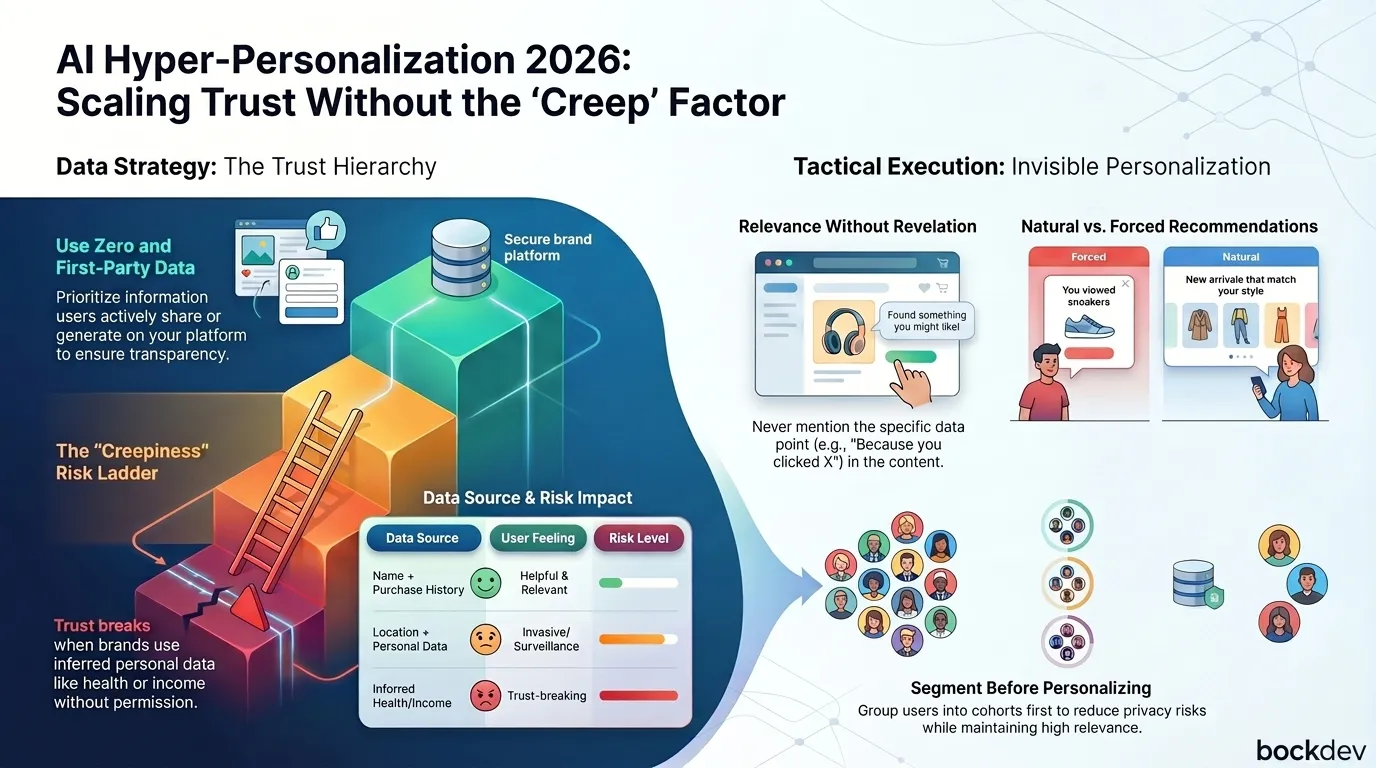
The difference between personalization and creepy personalization is usually the data source. Using what someone told you feels helpful. Using what you inferred without permission feels like surveillance.
The biggest mistake is over-indexing on data without thinking about the experience. Brands collect everything they can, then throw it all into the content engine.
The result is content that is technically accurate but emotionally off-putting. Users do not want to feel profiled. They want to feel understood.
Here is a quick comparison:
Approach
How It Feels to Users
Risk Level
Uses name + purchase history
Helpful, relevant
Low
References browsing behavior explicitly
Slightly uncomfortable
Medium
Combines location + recent searches + personal data
Invasive, surveillance-like
High
Uses inferred personal attributes (health, income)
Unacceptable, trust-breaking
Very High
The sweet spot is relevance without revelation. You can show someone content tailored to their interests without telling them you know their interests.
Each layer talks to the next. The data layer feeds signals to the AI content layer, which generates personalized variants, and the delivery layer pushes them to users at the right time.
The core of scalable personalization is a prompt-driven content engine. Instead of writing one piece of content and sending it to everyone, you write a prompt template that injects user context dynamically.
Here is a simple example using the Anthropic API:
python
import anthropicdef generate_personalized_email(user_data: dict) -> str: client = anthropic.Anthropic() prompt = f""" Write a short, friendly email for a SaaS product. User context: - Name: {user_data['name']} - Industry: {user_data['industry']} - Recent activity: {user_data['last_action']} - Subscription tier: {user_data['tier']} Rules: - Do not mention specific data points directly (no "we saw you clicked X") - Make recommendations feel natural, not algorithmic - Keep it under 120 words - Tone: helpful and professional """ message = client.messages.create( model="claude-opus-4-6", max_tokens=300, messages=[{"role": "user", "content": prompt}] ) return message.content[0].text# Example usageuser = { "name": "Sarah", "industry": "E-commerce", "last_action": "viewed the analytics dashboard", "tier": "Pro"}email_body = generate_personalized_email(user)print(email_body)
The key detail here is the "do not mention specific data points directly" rule in the prompt. That single instruction is what separates helpful from creepy.
Privacy-First Personalization: The Rules That Actually Matter
Privacy regulations like GDPR and CCPA are not going away. But beyond legal compliance, users in 2026 are more privacy-aware than ever. Brands that respect this win trust. Brands that ignore it lose users.
Here are the core principles for privacy-first personalization:
1. Use only zero-party and first-party data by default. Zero-party data is what users actively share (preferences, quiz answers, wishlist items). First-party data is what they generate on your platform (clicks, purchases). Both are fair game. Third-party data is increasingly unreliable and risky.
2. Never make the personalization visible. Do not say "because you viewed X." Just surface the relevant content. The recommendation should feel intuitive, not like a readout from your database.
3. Give users control. A simple preference center where users can adjust what they see goes a long way. It builds trust and improves your data quality at the same time.
4. Segment before you personalize. AI does not need individual-level data to be effective. Segment users into cohorts first (by behavior, industry, lifecycle stage), then personalize within those groups. This reduces privacy risk while keeping content relevant.
Here are three real-world examples of brands doing this well:
E-commerce product recommendations Instead of "You recently viewed sneakers," the email says "New arrivals that match your style." Same signal, completely different feel.
SaaS onboarding flows A project management tool detects that a user has not created their first project after 3 days. Instead of a generic nudge, the AI generates a tip tailored to their job title: "Most marketing managers start by building a campaign tracker. Here is a template."
Media and content platforms A news app identifies that a user reads mostly business and tech content on weekday mornings. The AI curates a personalized briefing for that exact context, without ever saying "we track when you read."
Measuring Whether Your Personalization Is Working
Personalization only works if it drives real outcomes. Track these metrics:
Metric
What It Tells You
Click-through rate by segment
Which cohorts respond to which content types
Unsubscribe rate
Whether content feels relevant or intrusive
Time-on-page for personalized content vs. generic
Engagement quality
Conversion rate per content variant
Which AI-generated variants actually convert
Preference center usage
Whether users trust you enough to share preferences
If unsubscribe rates go up after you add personalization, the content is feeling invasive, not helpful. Dial back the explicitness of your data signals in the prompts.
1. What is the difference between personalization and hyper-personalization?
Regular personalization uses basic attributes like name or location. Hyper-personalization uses behavioral signals, real-time context, and AI to create content that feels uniquely tailored to each individual at every touchpoint.
2. What data should I use for AI personalization?
Start with zero-party data (what users tell you directly) and first-party data (what they do on your platform). Avoid third-party data wherever possible. It is less reliable and creates privacy and compliance risks.
3. How do I personalize content without making users feel watched?
Never surface the signal in the content. Do not say "because you clicked X." Just show the relevant content. The recommendation should feel intuitive, not like a database readout.
4. Can small brands do hyper-personalization without a big tech team?
Yes. Tools like Klaviyo, Braze, and Dynamic Yield provide AI personalization out of the box. You do not need to build a custom LLM pipeline to get started. Begin with email segmentation and basic behavioral triggers.
5. What is the best AI model to use for content personalization?
It depends on your use case. For short-form content like emails or push notifications, faster and cheaper models work well. For more nuanced long-form content, use more capable models. Always test outputs before deploying at scale.
6. How do I handle GDPR compliance with AI personalization?
Ensure you have a lawful basis for processing user data (usually consent or legitimate interest). Provide a clear privacy policy, give users the ability to opt out, and never use sensitive personal categories (health, religion, etc.) for personalization without explicit consent.
7. What is a Customer Data Platform (CDP) and do I need one?
A CDP collects, unifies, and activates user data from multiple sources. It is not required for basic personalization, but becomes essential when you are pulling behavioral signals from multiple platforms (website, app, email, CRM). Segment and Twilio are popular options.
8. How often should I refresh AI-generated personalized content?
At minimum, refresh content when a user's behavior changes significantly (a new purchase, a long inactive period, a subscription change). For high-frequency platforms like apps or news sites, real-time or daily refresh is ideal.
9. Is AI-generated personalized content detectable by users?
Users rarely notice if the content is high quality and contextually relevant. Where it breaks down is when the output is generic, repetitive, or clearly formulaic. Always review AI output quality with human oversight, especially early on.
10. What is zero-party data and why is it better?
Zero-party data is information a user intentionally shares with you, like survey answers, preference settings, or wishlist items. It is more accurate than inferred data, always consented to, and far less likely to feel creepy when used for personalization.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,