Appearance

GRPO Explained: The Efficiency Shortcut Powering Modern Reasoning Models
Learn what GRPO (Group Relative Policy Optimization) is, how it differs from PPO, and why it powers efficient reasoning models like DeepSeek-R1, with code examples using Hugging Face TRL.
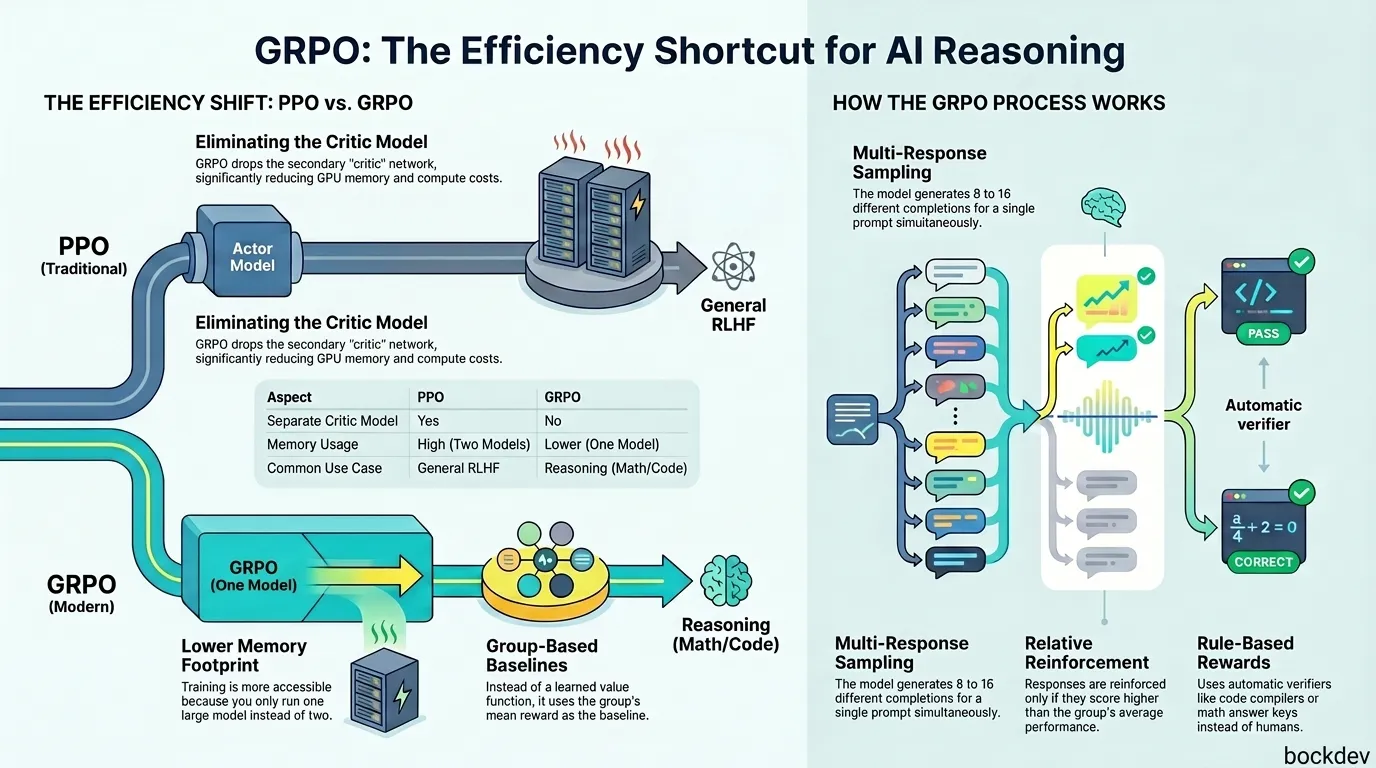
Training a reasoning model used to mean running two huge neural networks at once. One network generates answers. The other one, called a critic, grades those answers. That second network eats up GPU memory and slows everything down.
If you have ever tried to fine-tune a language model with reinforcement learning, you probably hit this wall. The critic model alone can be as big as the model you are training. Compute costs double, training gets fragile, and small teams get priced out of reasoning model research entirely.
GRPO (Group Relative Policy Optimization) fixes this. It drops the critic model completely and replaces it with a much simpler idea: compare a group of answers to each other instead of grading each one in isolation. This is the technique behind DeepSeek-R1 and DeepSeekMath, and it is now a standard tool for training reasoning models efficiently.
What Is GRPO, in Plain Terms
GRPO is a reinforcement learning method used to fine-tune large language models, especially for reasoning tasks like math and coding.
Instead of using a separate "critic" model to judge how good a response is, GRPO does this:
- Give the model one prompt.
- Ask it to generate a group of different answers (say, 8 or 16).
- Score each answer with a reward function.
- Compare each answer's score to the group's average.
- Push the model toward the better-than-average answers and away from the worse-than-average ones.
That's it. No second model. No separate value function. Just answers compared against their own peer group.
GRPO was introduced in the DeepSeekMath paper and later used to train DeepSeek-R1, which is what brought it widespread attention.
Why GRPO Exists: The Problem With PPO
Most RLHF (reinforcement learning from human feedback) pipelines before GRPO relied on PPO (Proximal Policy Optimization). PPO works well, but it has a costly requirement.
PPO needs a value function model that estimates how good a state is at every single token. Training this model is expensive, and in LLMs the reward is usually only known at the very end of a response (was the final answer correct?), which makes that value model hard to train accurately.
GRPO's fix is simple: skip the value function. Use the group's own statistics (mean and standard deviation of rewards) as the baseline instead.
| Aspect | PPO | GRPO |
|---|---|---|
| Needs a separate value/critic model | Yes | No |
| Memory footprint | High (two large models) | Lower (one model) |
| Baseline for advantage | Learned value function | Group mean reward |
| Reward granularity needed | Per-token estimate helps | Works with one reward per full response |
| Compute cost | Higher | Lower |
| Common use case | General RLHF, alignment | Reasoning tasks (math, code, logic) |
How the Math Works (Without the Jargon)
For each prompt, GRPO samples a group of responses, for example 8 completions. Each one gets a reward score from a reward function.
Then GRPO calculates an "advantage" for each response by standardizing its score against the group:
advantage_i = (reward_i - mean(group_rewards)) / (std(group_rewards) + epsilon)Responses that scored above the group average get a positive advantage and are reinforced. Responses below average get pushed down. The small epsilon just prevents division by zero when all rewards in a group are identical.
This is the entire trick. The "group" acts as its own baseline, so you never need to train a separate model to know what "average" looks like.
GRPO also keeps a KL-divergence penalty against a reference policy (usually the original pretrained model), which stops the model from drifting too far and collapsing into repetitive or degenerate outputs.
What Makes the Reward Function
GRPO does not require human-labeled preference data. It just needs a way to verify whether an answer is good. This is usually done with simple, programmable reward functions rather than another large model.
Common reward signals used in practice:
- Correctness reward: Does the final answer match the expected answer? (math problems)
- Format reward: Did the model follow the required output structure, like wrapping reasoning in tags?
- Code execution reward: Does the code compile? Does it pass unit tests? Does it run without errors?
- Length or efficiency reward: Penalize unnecessarily long or short responses.
Because these rewards come from rules or tools (a compiler, a unit test, an answer-checker) rather than a trained judge model, GRPO pipelines are cheaper to build and easier to debug. However, designers must be careful when configuring automated rewards to avoid problems like reward hacking, where the model finds shortcuts to maximize the score without learning the actual task.
A Minimal GRPO Training Example
Hugging Face's TRL library has a built-in GRPOTrainer that handles the group sampling and advantage calculation for you. Here is a minimal setup using a smaller base model, which reflects the broader small-model renaissance in AI development:
python
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
# 1. Load a dataset of prompts
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
# 2. Define a reward function
def accuracy_reward(completions, answers, **kwargs):
"""Reward 1.0 if the final answer matches, else 0.0"""
rewards = []
for completion, answer in zip(completions, answers):
rewards.append(1.0 if answer in completion else 0.0)
return rewards
# 3. Configure training
training_args = GRPOConfig(
output_dir="grpo_output",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
logging_steps=10,
)
# 4. Initialize and train
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-0.5B-Instruct",
reward_funcs=accuracy_reward,
args=training_args,
train_dataset=dataset,
)
trainer.train()You can also combine multiple reward functions. TRL adds up the scores (or uses a weighted sum if you set reward_weights):
python
from trl import GRPOTrainer
def format_reward(completions, **kwargs):
"""Reward responses that follow the expected tag structure"""
return [1.0 if "<answer>" in c and "</answer>" in c else 0.0 for c in completions]
def accuracy_reward(completions, answers, **kwargs):
return [1.0 if a in c else 0.0 for c, a in zip(completions, answers)]
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-0.5B-Instruct",
reward_funcs=[format_reward, accuracy_reward],
args=training_args,
train_dataset=dataset,
)
trainer.train()A Typical GRPO Project Layout
If you are setting up your own GRPO fine-tuning project, a simple structure looks like this:
grpo-project/
├── data/
│ └── train_prompts.jsonl # prompts the model will respond to
├── rewards/
│ ├── accuracy_reward.py # checks final answer correctness
│ └── format_reward.py # checks output structure
├── train_grpo.py # main training script
├── eval.py # evaluate the trained model
└── requirements.txtA minimal requirements.txt:
trl>=0.14.0
transformers>=4.47.0
datasets>=3.2.0
peft>=0.14.0
accelerate>=1.2.0Where GRPO Shines (and Where It Doesn't)
GRPO works best when you can verify correctness automatically. Think math problems with a known final answer, or code that you can compile and test. In software engineering tasks, relying on test execution as a reward helps ensure the model doesn't just produce plausible-looking but broken code.
It is less natural for tasks where "quality" is subjective and there is no clean reward signal, like open-ended creative writing or nuanced tone alignment. In those cases, preference-based methods like DPO or RLHF with a learned reward model can still be a better fit.
Quick Recap
GRPO removes the expensive critic model from reinforcement learning fine-tuning. It replaces it with a simple comparison: generate a group of answers, score them, and reinforce the ones that beat the group average.
This makes it cheaper, more memory-efficient, and easier to scale, which is exactly why it became the backbone of DeepSeek-R1 and many reasoning models that followed.
Q&A
1. What does GRPO stand for?
Group Relative Policy Optimization. It's a reinforcement learning method for fine-tuning language models.
2. Is GRPO the same as PPO?
No. GRPO is built on top of PPO's ideas but removes the separate value/critic model, using group statistics as the baseline instead.
3. Does GRPO need labeled data?
No. It needs a way to verify or score responses, which can come from rule-based reward functions, not necessarily human labels.
4. Why did DeepSeek use GRPO?
To train DeepSeekMath and DeepSeek-R1 efficiently, without the memory and compute cost of a full critic model.
5. What is a "group" in GRPO?
A set of multiple responses generated by the model for the same prompt, usually 4 to 16 completions, used to calculate a relative baseline.
6. Can I use GRPO for non-math tasks?
Yes, as long as you can write a reward function that scores correctness or quality, such as code tests, format checks, or rule-based scoring.
7. What library should I use to try GRPO myself?
Hugging Face's TRL library has a ready-to-use GRPOTrainer class for this purpose.
8. Does GRPO use a reference model?
Yes. GRPO keeps a KL-divergence penalty against a reference policy to prevent the model from drifting too far during training.
9. Is GRPO cheaper than PPO?
Generally yes, mainly because it skips training a separate value function model, which reduces memory and compute needs.
10. What's the biggest limitation of GRPO?
It depends heavily on having a reliable, automatic way to score responses. Tasks without a clear verification signal are harder to fit into this framework.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- What is GRPO? Group Relative Policy Optimization Explained - https://www.datacamp.com/blog/what-is-grpo-group-relative-policy-optimization
- GRPO in Reinforcement Learning Explained - https://www.digitalocean.com/community/conceptual-articles/group-relative-policy-optimization-reinforcement-learning
- Implementing GRPO in TRL - https://huggingface.co/learn/llm-course/chapter12/4
- GRPO Trainer Documentation - https://huggingface.co/docs/trl/grpo_trainer
- Post training an LLM for reasoning with GRPO in TRL - https://huggingface.co/learn/cookbook/en/fine_tuning_llm_grpo_trl