Appearance

Native Video Understanding: Beyond "Stitched Photo" Analysis
Learn how native video understanding differs from frame-sampling AI methods, why "stitched photo" analysis misses motion and context, and how to choose the right approach for your video AI project.
You upload a video to an AI tool and ask, "What happened in this clip?" It gives you a decent answer. But ask a follow-up like "Why did the person react that way?" or "What changed right before the accident?" and the answer falls apart. The AI clearly didn't watch the video. It glanced at a few photos from it.
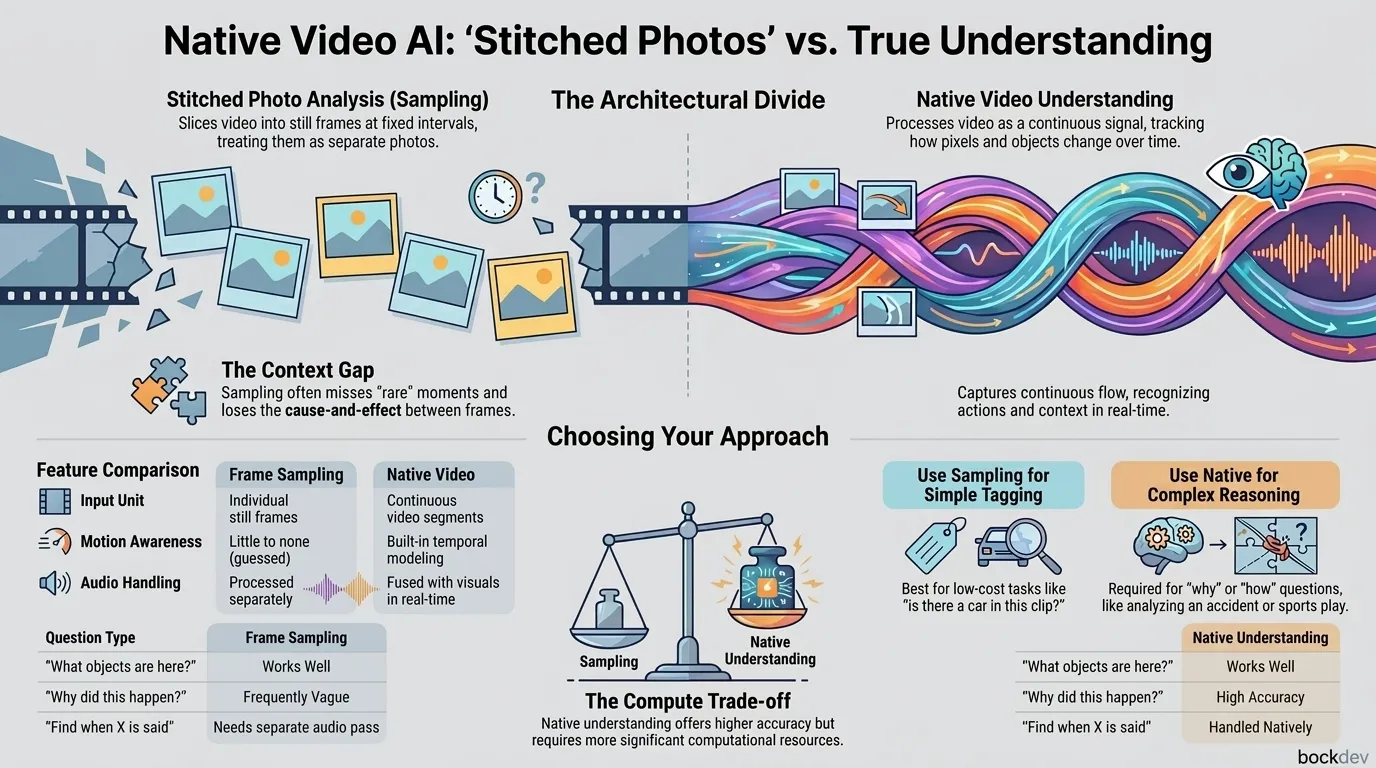
This is the dirty secret behind a lot of "video AI" products today. Many of them don't actually process video as video. They slice it into still frames, treat each frame like a separate photo, and then try to guess the story by stitching the captions together. It works for simple stuff. It breaks down the moment you need real understanding of motion, timing, or cause and effect.
Native video understanding takes a different path. Instead of judging a movie by a handful of screenshots, it processes the video as a continuous signal, motion, audio, and time included. Below, we'll break down what that actually means, how it's different from frame sampling, and how to think about it when building or choosing a video AI system.
What "Stitched Photo" Analysis Actually Means
Most early video AI tools work like this: pull out frames at fixed intervals (say, 1 frame per second), run each frame through an image model, then glue the results together with a language model.
It sounds efficient. A 10-minute video at 30 frames per second has 18,000 frames. Nobody wants to analyze all of them, so sampling cuts that down to something manageable, often just a few hundred frames.
The problem is what gets lost between the samples:
- Motion disappears. A still frame can't tell you if someone is sitting down or standing up.
- Cause and effect gets guessed, not observed. If the AI didn't see the frame where the glass tipped over, it can't really explain why the floor is wet.
- Audio and visuals get analyzed separately, then forced back together, which causes timing mismatches.
- Rare but important moments get skipped if they fall between sampled frames.
This is why these systems are sometimes called "stitched photo" analyzers. They're really just photo analysis tools wearing a video costume.
What Native Video Understanding Does Differently
Native video understanding models are trained to process video as its own data type, not as a sequence of unrelated images. They typically combine:
- Temporal modeling: tracking how pixels, objects, and scenes change across time, not just within one frame.
- Audio-visual fusion: processing sound and image together so a spoken word and the matching mouth movement are understood as one event.
- Variable-resolution sampling: looking closely at frames where something important is happening, and skimming through frames where nothing changes.
- Long-context memory: keeping track of what happened minutes ago in the video, not just the last few seconds.
This is the same shift that happened earlier in language AI: early models read text word by word with little memory of earlier context. Newer models track relationships across the entire document. Native video models are doing that for time and motion instead of just words.
Frame Sampling vs Native Video Understanding
| Aspect | Frame Sampling ("Stitched Photo") | Native Video Understanding |
|---|---|---|
| Input unit | Individual still frames | Continuous video segments |
| Motion awareness | Little to none | Built in |
| Audio handling | Processed separately, merged later | Fused with visuals in real time |
| Compute cost | Lower | Higher, but improving |
| Good for | Simple object/scene tagging | Action recognition, cause-effect, summarization |
| Common failure | Misses events between sampled frames | Struggles with extremely long videos without chunking |
| Example use case | "Does this frame contain a car?" | "Why did the car swerve?" |
Frame sampling isn't useless. It's cheap, fast, and fine for simple tagging tasks. For efficiency, AI might sample every 3rd frame instead of every frame, which keeps costs down for basic detection work. The trouble starts when people expect frame sampling to deliver native-level reasoning.
How Frame Sampling Works Under the Hood
A simple sampling pipeline usually looks like this:
video_pipeline/
├── input/
│ └── raw_video.mp4
├── extract_frames/
│ ├── frame_0001.jpg
│ ├── frame_0031.jpg # every 30th frame (1 fps from 30fps video)
│ └── frame_0061.jpg
├── analyze/
│ └── image_model_output.json
└── stitch/
└── final_summary.txtA basic Python sampling step often looks like this:
python
import cv2
video = cv2.VideoCapture("raw_video.mp4")
fps = video.get(cv2.CAP_PROP_FPS)
sample_rate = int(fps) # grab 1 frame per second
frame_count = 0
saved = 0
while True:
success, frame = video.read()
if not success:
break
if frame_count % sample_rate == 0:
cv2.imwrite(f"frame_{saved:04d}.jpg", frame)
saved += 1
frame_count += 1
video.release()This works, but notice what's missing: there's no logic here for "did something important happen between frames?" It samples on a fixed clock, not based on content.
Smarter sampling methods fix part of this by making the sampling rate adaptive to the question being asked. Query-adaptive frame sampling processes only the most relevant frames in real time, addressing the problem of sampling redundant or irrelevant frames. That's a real improvement, but it's still sampling. It's choosing which photos to look at more carefully, not watching the video continuously.
How Native Video Understanding Is Set Up
Native approaches usually treat video as chunks with overlap, so context isn't lost at chunk boundaries, and combine multiple signal types per chunk:
video_pipeline/
├── input/
│ └── raw_video.mp4
├── chunks/
│ ├── chunk_000_0-20s.mp4
│ ├── chunk_001_15-35s.mp4 # 5s overlap with previous chunk
│ └── chunk_002_30-50s.mp4
├── extract/
│ ├── audio_transcript.json
│ ├── visual_embeddings.json
│ └── ocr_text.json
└── output/
└── unified_summary.jsonA configuration for this kind of pipeline might look like:
python
CHUNK_SECONDS = 20 # length of each video chunk
OVERLAP_SECONDS = 5 # overlap so events aren't cut in half
FRAMES_PER_CHUNK = 8 # denser sampling within each chunk
MODALITIES = ["audio", "visual", "ocr"]
def process_chunk(chunk_path, modalities):
results = {}
if "audio" in modalities:
results["transcript"] = run_speech_to_text(chunk_path)
if "visual" in modalities:
results["visual_embedding"] = run_video_encoder(chunk_path)
if "ocr" in modalities:
results["on_screen_text"] = run_ocr(chunk_path)
return resultsThe chunking with overlap matters a lot. Splitting a video into chunks is a common strategy for handling the volume of data, and the system needs to make sure important details aren't missed, since critical information might appear in spoken audio in one part and on-screen text in another. Overlap is what keeps an event from getting sliced in half between two chunks.
Why This Matters for Real Use Cases
The difference shows up clearly once you compare what each approach can answer:
| Question Type | Frame Sampling | Native Understanding |
|---|---|---|
| "What objects appear in this video?" | Works well | Works well |
| "What is this person doing?" | Often works | Works well |
| "Why did this happen?" | Frequently wrong or vague | Generally more accurate |
| "Summarize the whole video" | Misses transitions | Captures flow and sequence |
| "Find the moment someone says X" | Needs separate audio pass | Handled natively |
If your use case is tagging products in e-commerce videos or flagging obvious content categories, frame sampling is fine and cheaper. If you're building tools for surveillance analysis, sports breakdowns, customer support call review, or anything involving "why" or "how" questions, native understanding is worth the extra compute cost.
Practical Guidance: Choosing an Approach
A few concrete decision points:
1. Check your question complexity. If your queries are like "is there a dog in this video," sampling works fine. If they're like "did the dog react before or after the doorbell rang," you need temporal awareness.
2. Check your video length. Short clips (under a minute) are forgiving either way. Long videos need chunking with overlap, regardless of method, or context gets lost.
3. Check your modalities. If audio matters as much as visuals (meetings, interviews, tutorials), make sure your pipeline fuses both instead of analyzing them in separate passes.
4. Budget for compute. Native video models cost more to run. Some platforms now offer middle-ground solutions: heavier processing only on segments flagged as "high activity," lighter sampling elsewhere.
python
def adaptive_pipeline(video_path):
activity_scores = detect_activity_segments(video_path)
for segment in activity_scores:
if segment.activity_level > THRESHOLD:
run_native_analysis(segment)
else:
run_basic_sampling(segment)This hybrid pattern is becoming common: spend the expensive native processing only where it earns its cost.
Where the Field Is Headed
Video AI is moving the same direction NLP moved years ago: from shallow, snapshot-based methods toward models that hold context over long stretches of input. Some platforms now combine multiple extraction methods (vision, audio, OCR, face detection) into one pipeline instead of stitching together separate tools. This combines visual understanding, audio transcription, OCR, and face detection into composable extraction pipelines with retrieval-ready output, which is a sign the industry is moving away from single-modality, frame-only analysis.
Research is also pushing toward smarter frame selection that beats plain uniform sampling. In one benchmark comparison, a generative frame-selection method scored noticeably higher than both uniform sampling and other learned samplers on long-video tasks, improving over a uniform sampling baseline and over other specialized video-language models for frame sampling. That's progress, but it's worth noting these are still improvements within the sampling paradigm, not a replacement for full native processing.
Quick Recap
- "Stitched photo" analysis means treating a video as a set of disconnected still images.
- It's fast and cheap but misses motion, timing, and cause-effect relationships.
- Native video understanding processes video as a continuous stream, fusing audio and visual signal over time.
- Chunking with overlap is the standard way to handle long videos in native pipelines.
- Pick your approach based on question complexity, video length, and budget, not by default.
Frequently Asked Questions
1. What does "stitched photo" analysis mean in video AI?
It refers to systems that break a video into individual still frames, analyze each frame separately like a photo, and then combine the results into a summary, without truly modeling motion or time.
2. Is frame sampling always a bad approach?
No. It's a practical, lower-cost method that works well for simple tasks like object detection or basic scene tagging. It struggles with questions about motion, sequence, or cause and effect.
3. How is native video understanding different from frame sampling?
Native video understanding processes the video as a continuous signal, including motion between frames and audio, rather than analyzing isolated snapshots and reconstructing a story afterward.
4. Why does audio matter so much in video understanding?
Many key details, like what someone says or implies, only exist in audio. Critical information might appear in spoken audio in one part of a video and on-screen text in another, so a system has to catch both to avoid missing context.
5. What is chunking, and why use overlap between chunks?
Chunking splits a long video into shorter segments for processing. Overlap (a few seconds shared between consecutive chunks) prevents an event from being cut in half right at a chunk boundary.
6. Does native video understanding cost more to run?
Generally yes, because it processes more data per second of video and fuses multiple signal types. Hybrid pipelines that apply heavier analysis only to "high activity" segments can help control this cost.
7. Can frame sampling be made smarter instead of switching to native processing?
Yes. Query-adaptive sampling adjusts which frames get analyzed based on the specific question being asked, rather than sampling at a fixed rate regardless of content.
8. What kinds of projects actually need native video understanding?
Use cases involving "why" or "how" questions: surveillance analysis, sports play breakdowns, call/meeting review, accident analysis, and detailed video summarization.
9. What kinds of projects are fine with basic frame sampling?
Simple tagging tasks: detecting whether an object/logo appears, basic content moderation categories, or coarse scene classification where exact timing doesn't matter.
10. How many frames does a typical video actually have?
A standard 30 fps video produces 1,800 frames per minute. A one-hour movie at 30 frames per second works out to 108,000 frames total, which is why sampling exists in the first place: analyzing every single frame is rarely practical.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- Sullam Jeoung, et al (2024). Adaptive Video Understanding Agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning - https://arxiv.org/pdf/2410.20252
- Linli Yao et al (2025). Generative Frame Sampler for Long Video Understanding - https://arxiv.org/pdf/2503.09146
- Best AI Video Analysis Tools in 2026 - https://mixpeek.com/curated-lists/best-ai-video-analysis-tools
- AI-Driven Video Understanding: A Real-World Walk-through - https://medium.com/@mail2mhossain/ai-driven-video-understanding-a-real-world-walk-through-18ee86c96a86