Appearance

KV Cache Compression Explained: Fix the Memory Wall in Long-Context LLMs
KV cache compression is a suite of techniques (such as quantization, eviction, and low-rank representations) designed to reduce the memory footprint of key-value states in transformer models, preventing VRAM bottlenecks during long-context LLM inference.
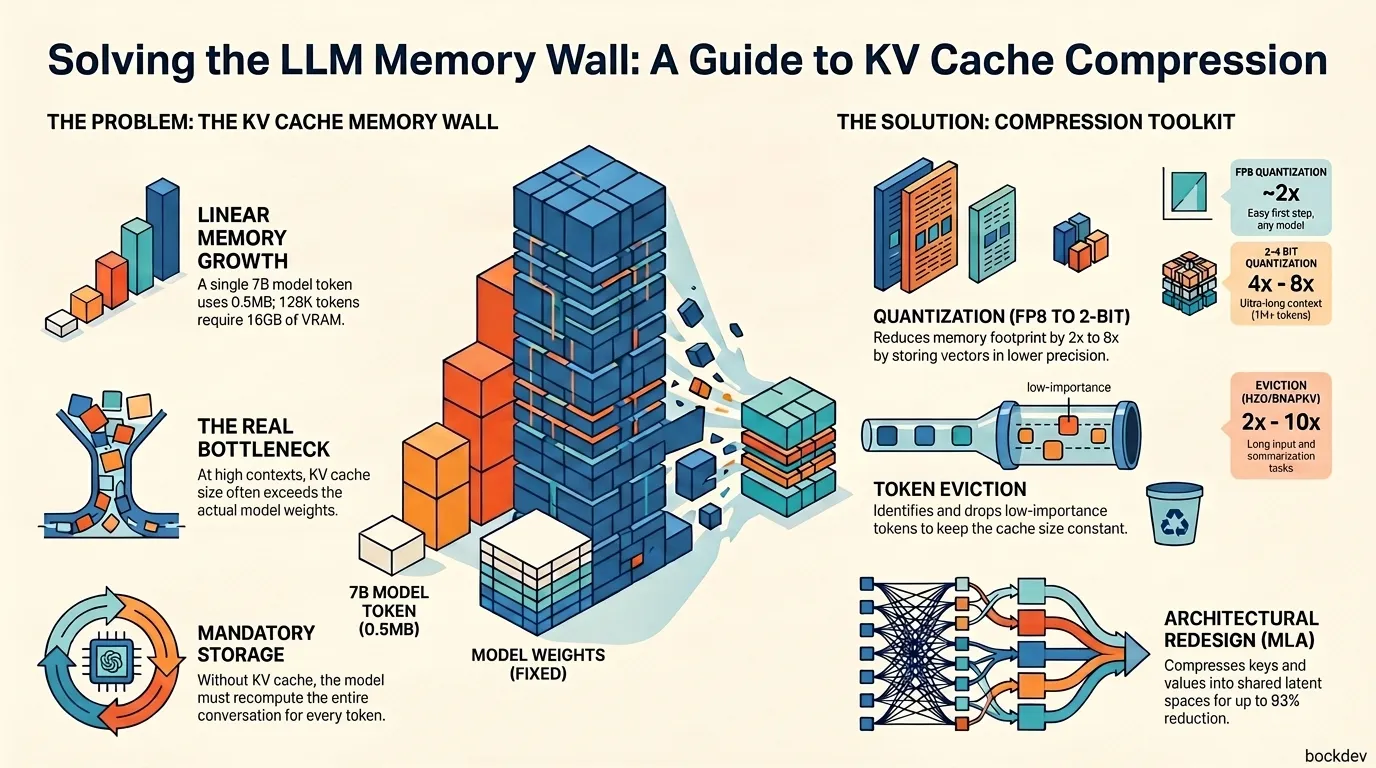
Ever tried running a model with a 128K context window and watched your GPU memory disappear before the first token even comes out? You're not imagining it. The model itself isn't the problem. Something else is quietly eating your VRAM.
That something is the KV cache. It's the part of inference nobody talks about until it crashes their server. Every token you feed into the model gets stored as "memory" so the model doesn't have to recompute it. Sounds efficient, right? It is, until your context gets long. Then this cache grows so fast it can cost more memory than the model weights themselves.
The good news is that this is a solved problem, just not a well-known one. KV cache compression is the toolkit that lets you keep long context without buying more GPUs. Let's break down what it is, why it matters, and how to actually use it.
What Is the KV Cache, Really
When a transformer processes text, every token generates a "key" and a "value" vector inside the attention layers. These get saved so future tokens can look back at past ones without redoing the math.
That saved memory is the KV cache. It's not optional. Without it, generating each new token would mean reprocessing the entire conversation from scratch.
The catch is size. A single token's KV cache in a 7B parameter model takes about 0.5 MB of GPU memory, so a 10,000 token prompt alone uses around 5 GB. Now stretch that to 128K tokens and you can see the wall coming.
Rough memory math for KV cache:
KV cache size = 2 × layers × heads × head_dim × tokens × precision_bytes
Example: Llama 3.1 8B, FP16, 128K context
≈ 16 GB just for KV cache (more than the model weights at 4-bit)Why KV Cache Limits Context Window (The Memory Wall)
Model weights are fixed. They take the same memory no matter how long your prompt is. The KV cache is the opposite: it grows linearly with every token you add.
That means two requests with the same model can have wildly different memory needs. A short chat message is cheap. A 100-page document dropped into context is not.
At FP16, the KV cache alone uses roughly 4GB at 32K context and 16GB at 128K for an 8B model, which ends up costing more memory than the model weights themselves when quantized to 4-bit. This is the real bottleneck behind "out of memory" errors during long-context inference, not the model size.
How to Compress KV Cache: 3 Core Techniques
There isn't one silver bullet. Most production systems combine a few of these approaches.
1. Quantization: Store Numbers with Fewer Bits
Instead of storing each key/value number in 16-bit precision, store it in 8-bit or even lower. Less precision, way less memory, usually a tiny accuracy hit.
bash
# vLLM: enable FP8 KV cache quantization (no calibration, simplest setup)
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--kv-cache-dtype fp8 \
--max-model-len 131072Quantizing the KV cache to FP8 reduces its memory footprint, which increases the number of tokens that fit in the cache and improves throughput, primarily by roughly doubling the available cache space for longer contexts.
For better accuracy, you can calibrate scales on real data instead of using the default uncalibrated approach:
python
from llmcompressor import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_ID = "meta-llama/Llama-3.1-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
recipe = QuantizationModifier(targets="Linear", scheme="FP8_DYNAMIC")
oneshot(model=model, recipe=recipe, dataset="HuggingFaceH4/ultrachat_200k")
SAVE_DIR = "Llama-3.1-8B-Instruct-FP8-KV"
model.save_pretrained(SAVE_DIR, save_compressed=True)
tokenizer.save_pretrained(SAVE_DIR)Then load it in vLLM the same way:
bash
vllm serve ./Llama-3.1-8B-Instruct-FP8-KV --kv-cache-dtype fp8For even more aggressive compression, methods like KIVI push down to 2-bit asymmetric quantization for the cache, and KVQuant targets sub-4-bit precision for contexts up to millions of tokens.
2. Eviction: Throw Away What You Don't Need
Not every past token matters equally. Eviction methods score tokens by importance and drop the low-value ones, keeping the cache size roughly constant.
StreamingLLM pattern (sliding window + attention sinks):
[sink tokens] [............ dropped ............] [recent window]
kept evicted keptA simple version of this idea in pseudocode:
python
def evict_kv_cache(kv_cache, attention_scores, keep_ratio=0.5):
"""Keep only the top-k most attended tokens."""
num_tokens = kv_cache.shape[1]
keep_n = int(num_tokens * keep_ratio)
importance = attention_scores.mean(dim=0) # average across heads
top_indices = importance.topk(keep_n).indices
return kv_cache[:, top_indices, :]Methods like H2O and SnapKV have shown that keeping less than 50% of the KV cache barely hurts model performance. Other approaches, like PyramidKV, keep more tokens in lower layers and fewer in deeper layers, since deeper layers tend to need less raw context.
3. Low-Rank and Architectural Compression
This approach changes how the cache is structured in the first place, rather than shrinking it after the fact. Multi-head Latent Attention (MLA), used in DeepSeek-V2, is the most notable example.
MLA achieves a 93.3% KV cache reduction in DeepSeek-V2 by compressing keys and values into a shared low-rank latent space instead of storing them per-head in full size.
Standard Multi-Head Attention:
Each head stores its own full-size K, V → big cache
Multi-Head Latent Attention (MLA):
All heads share one compressed latent K/V → tiny cache
(reconstructed back to full size only during attention)Other architectural fixes include Grouped Query Attention (GQA), which shares key/value heads across multiple query heads, and hybrid sliding-window attention used in newer models that simply don't attend to the full context at every layer.
Comparing the Main Approaches
| Method | How it works | Typical savings | Accuracy impact | Best for |
|---|---|---|---|---|
| FP8 quantization | Lower bit precision for K/V | ~2x | Minimal | Easy first step, any model |
| 2-4 bit quantization (KIVI, KVQuant) | Ultra-low precision + calibration | 4-8x | Small, needs tuning | Very long context (1M+ tokens) |
| Eviction (H2O, SnapKV, PyramidKV) | Drop low-importance tokens | 2-10x | Small to moderate | Long input, summarization tasks |
| Low-rank (MLA) | Compress K/V into shared latent space | Up to ~93% | Requires training the architecture | New model designs, not existing models |
| GQA / hybrid attention | Share heads or skip full attention | 2-8x | Minimal | Any new model architecture |
A Practical Setup: Combining Methods
In real deployments, you rarely pick just one method. Here's a realistic stack for serving a long-context model on limited VRAM:
bash
vllm serve meta-llama/Llama-3.1-8B-Instruct \
--kv-cache-dtype fp8 \
--max-model-len 65536 \
--gpu-memory-utilization 0.90 \
--enable-chunked-prefillDirectory layout for a calibrated FP8 KV cache workflow:
project/
├── calibrate_kv.py # runs llmcompressor calibration
├── Llama-3.1-8B-FP8-KV/ # output: quantized model + scales
│ ├── config.json
│ ├── model.safetensors
│ └── kv_cache_scales.json
└── serve.sh # vllm serve command with --kv-cache-dtype fp8vLLM also supports skipping quantization on specific layers, such as sliding-window attention layers in models like GPT-OSS, where FP8 overhead doesn't pay off and BF16 ends up faster:
bash
vllm serve openai/gpt-oss-20b \
--kv-cache-dtype fp8 \
--kv-cache-dtype-skip-layers "20,21,22,23"Quick Checklist Before You Deploy
- Set your context window to what you actually need, not the maximum the model supports
- Start with FP8 KV cache quantization since it's a one-flag change
- Add calibration if accuracy drops matter for your task
- Layer in eviction (SnapKV/H2O-style) only if quantization alone isn't enough
- Check if your model architecture already uses GQA or MLA before adding more compression
Q&A
1. What exactly is stored in the KV cache?
The key and value vectors computed by attention layers for every token already processed, so the model can reuse them instead of recomputing attention from scratch.
2. Why does the KV cache grow instead of staying fixed like the model weights?
Because it stores one key/value pair per token per layer. More tokens in context means more entries, so it scales linearly with context length.
3. Is KV cache compression the same as model quantization?
No. Model quantization shrinks the weights. KV cache quantization shrinks the stored attention states. You can do either independently or both together.
4. Does FP8 KV cache quantization hurt output quality?
Usually very little. Most benchmarks show a small to negligible drop, especially with calibrated scales instead of default uncalibrated ones.
5. What's the easiest method to start with?
FP8 quantization. It's a single flag in vLLM (--kv-cache-dtype fp8) with no retraining needed.
6. When should I use eviction methods instead of quantization?
When your context is extremely long and you need to actually shrink the number of stored tokens, not just shrink each token's storage size.
7. Can I combine quantization and eviction?
Yes. They target different things, precision per token versus number of tokens kept, so they stack well together.
8. Does GQA replace the need for KV cache compression?
No, but it reduces the baseline cache size by sharing key/value heads across query heads, so it pairs well with quantization on top.
9. What's MLA and why is it different?
Multi-head Latent Attention compresses keys and values into a shared low-rank space at the architecture level, achieving very large reductions, but it requires the model to be built or trained with MLA from the start.
10. How do I know if KV cache is my actual bottleneck?
If you get out-of-memory errors that get worse as context length increases (not as batch size increases), the KV cache is very likely the cause.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- Xiang LIU, et al. (2025). ChunkKV: Semantic-Preserving KV Cache Compression for Efficient Long-Context LLM Inference - https://arxiv.org/pdf/2502.00299
- KV Cache: Why Context Length Eats Your VRAM (And How to Fix It) - https://insiderllm.com/guides/kv-cache-optimization-guide/
- Quantized KV Cache - vLLM Documentation - https://docs.vllm.ai/en/latest/features/quantization/quantized_kvcache/
- The State of FP8 KV-Cache and Attention Quantization in vLLM - https://vllm-project.github.io/2026/04/22/fp8-kvcache.html
- Top 10 KV Cache Compression Techniques for LLM Inference: Reducing Memory Overhead Across Eviction, Quantization, and Low-Rank Methods - https://www.marktechpost.com/2026/04/29/top-10-kv-cache-compression-techniques-for-llm-inference-reducing-memory-overhead-across-eviction-quantization-and-low-rank-methods/