Appearance

Gemma 4 on Amazon Bedrock: Getting Started with Google's Open-Weight AI Models
Learn how to use Gemma 4 models (31B, 26B-A4B, and E2B) on Amazon Bedrock. This guide covers setup, code examples, multimodal input, reasoning mode, tool calling, and production best practices.
You want powerful AI models in production, but you also need data privacy, regulatory compliance, and operational control. That usually feels like a trade-off. Use the cutting-edge model, or keep your data safe. Pick one.
Amazon Bedrock removes that trade-off. It hosts Google DeepMind's Gemma 4 family as a fully managed service, running inference entirely on AWS infrastructure. Your prompts and completions are never used to train models, and nothing is shared with third parties.
In this post, you will learn how to pick the right Gemma 4 variant, set up access, and call the API with real code examples covering text, images, streaming, tool calling, and reasoning mode.
What Is Gemma 4?
Gemma 4 is an open-weight model family from Google DeepMind, released under the Apache 2.0 license. It covers dense and mixture-of-experts (MoE) architectures, with every variant supporting reasoning mode, native function calling, and multimodal input (text plus images).
All three variants are available on Amazon Bedrock through the bedrock-mantle endpoint, which uses an OpenAI-compatible interface. This means if you are already using the OpenAI Python SDK, you only need to swap the base URL and model ID.
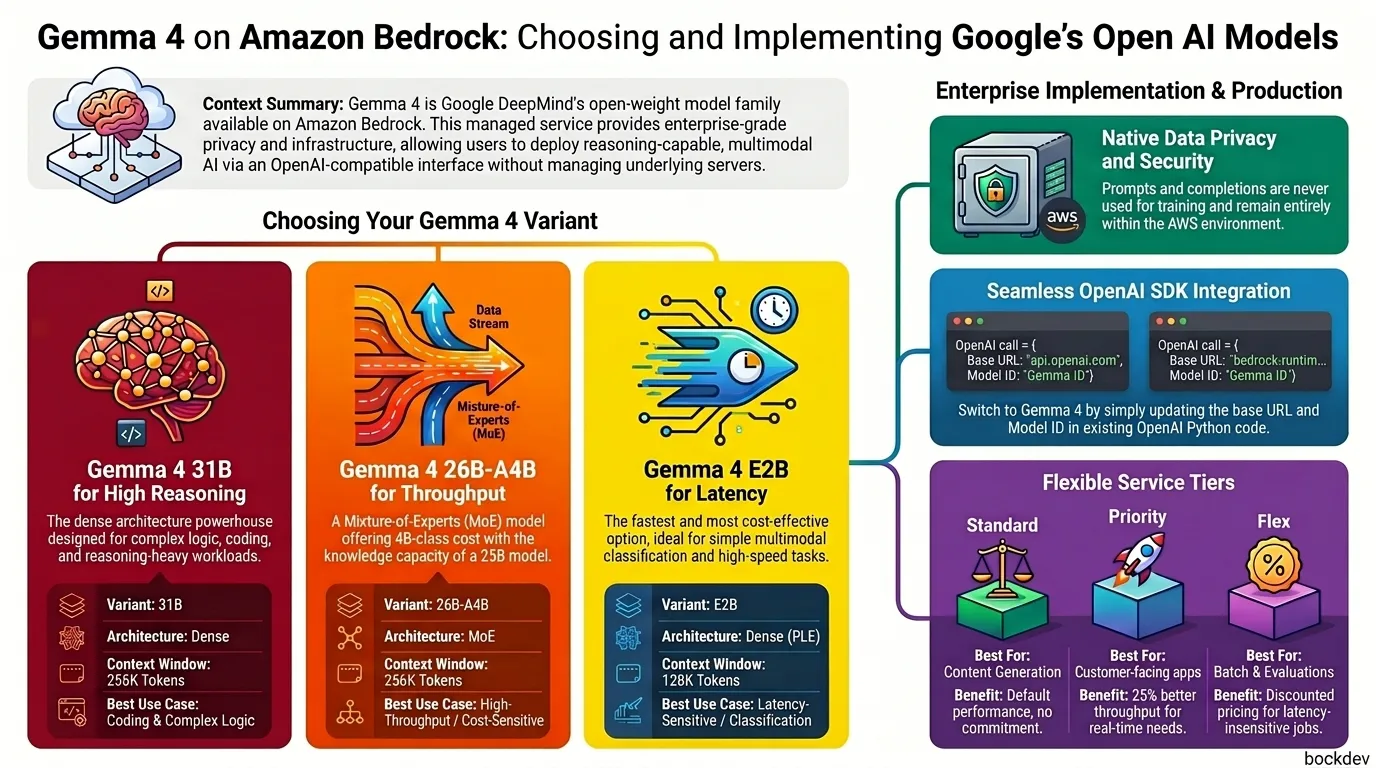
Gemma 4 Variants at a Glance
| Gemma 4 31B | Gemma 4 26B-A4B | Gemma 4 E2B | |
|---|---|---|---|
| Model ID | google.gemma-4-31b | google.gemma-4-26b-a4b | google.gemma-4-e2b |
| Architecture | Dense | Mixture-of-Experts | Dense (PLE) |
| Parameters | 30.7B total | 25.2B total / 3.8B active | 5.1B total / 2.3B effective |
| Context window | 256K tokens | 256K tokens | 128K tokens |
| Modalities | Text, image | Text, image | Text, image |
| Reasoning mode | Yes | Yes | Yes |
| Function calling | Native | Native | Native |
Choosing the Right Variant
| Your workload | Choose | Why |
|---|---|---|
| Reasoning-heavy or coding tasks | Gemma 4 31B | Strongest reasoning and coding, 256K context |
| Cost-sensitive at high throughput | Gemma 4 26B-A4B | MoE design: 4B-class cost with larger model knowledge |
| Latency-sensitive or multimodal classification | Gemma 4 E2B | Fastest and cheapest; use reasoning_effort=high |
All three variants share the same API surface, so you can build once and swap models without changing your code.
Prerequisites and Setup
You need an AWS account with permission to call the bedrock-mantle endpoint. The easiest way is to attach the AmazonBedrockMantleInferenceAccess managed IAM policy to your user or role.
The endpoint URL is:
https://bedrock-mantle.{region}.api.aws/openai/v1You will also need a short-term Amazon Bedrock API key. These expire automatically after a maximum of 12 hours. In production, store them in AWS Secrets Manager rather than environment variables.
Basic Text Completion
Use the OpenAI Python SDK and point it at the bedrock-mantle endpoint:
python
from openai import OpenAI
client = OpenAI(
api_key="<your-short-term-bedrock-api-key>",
base_url="https://bedrock-mantle.us-east-1.api.aws/openai/v1",
)
response = client.chat.completions.create(
model="google.gemma-4-31b",
messages=[
{"role": "user", "content": "Explain the benefits of mixture-of-experts architectures for production inference."}
],
max_tokens=512,
)
print(response.choices[0].message.content)If you are migrating from another OpenAI-compatible provider, this is likely all you need to change.
Multimodal Input (Images)
All Gemma 4 variants accept image input. The endpoint supports base64-encoded data URLs and Amazon S3 URLs (s3://). Public https:// image URLs are not supported.
Place image content before the text prompt for best results, following Google DeepMind's recommended input ordering.
python
import base64
with open("chart.png", "rb") as image_file:
image_b64 = base64.b64encode(image_file.read()).decode("utf-8")
data_url = f"data:image/png;base64,{image_b64}"
response = client.chat.completions.create(
model="google.gemma-4-31b",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": data_url}},
{"type": "text", "text": "Describe the trend shown in this chart."}
]
}],
)
print(response.choices[0].message.content)To use an S3 image instead, replace data_url with "s3://my-bucket/chart.png".
Streaming Responses
For chat or agent interfaces where you want to show tokens as they arrive, set stream=True:
python
stream = client.chat.completions.create(
model="google.gemma-4-31b",
messages=[
{"role": "user", "content": "Write a short poem about distributed systems."}
],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)
print()No additional IAM permissions are needed. Streaming uses the same bedrock-mantle:CreateInference permission as non-streaming calls.
Tool Calling (Function Calling)
Gemma 4 supports native function calling for agentic workflows. The pattern is: define tools, let the model call one, run the function yourself, return the result, get the final answer.
python
import json
from openai import OpenAI
client = OpenAI(
api_key="<your-short-term-bedrock-api-key>",
base_url="https://bedrock-mantle.us-east-1.api.aws/openai/v1",
)
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and country"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}]
messages = [{"role": "user", "content": "What's the weather like in Seattle?"}]
# Step 1: Send request with tool definitions
response = client.chat.completions.create(
model="google.gemma-4-31b",
messages=messages,
tools=tools,
tool_choice="auto",
)
assistant_message = response.choices[0].message
# Step 2: Check if the model wants to call a tool
if assistant_message.tool_calls:
messages.append(assistant_message)
for tool_call in assistant_message.tool_calls:
arguments = json.loads(tool_call.function.arguments)
location = arguments.get("location", "Unknown")
unit = arguments.get("unit", "fahrenheit")
# Step 3: Run the actual function
result = {
"location": location,
"temperature": 18 if unit == "celsius" else 64,
"unit": unit,
"condition": "Partly cloudy",
}
# Step 4: Return the result to the model
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result),
})
# Step 5: Get the final answer
final_response = client.chat.completions.create(
model="google.gemma-4-31b",
messages=messages,
tools=tools,
)
print(final_response.choices[0].message.content)
else:
print(assistant_message.content)Reasoning Mode
Reasoning mode makes the model show its thinking before giving a final answer. It is useful for complex multi-step problems and is enabled through the Responses API.
python
response = client.responses.create(
model="google.gemma-4-31b",
input="If a train leaves at 3pm at 60 km/h and another leaves an hour later at 90 km/h, when does the second catch up?",
reasoning={"effort": "high"},
)
# Final answer
print(response.output_text)
# The model's thought process
for item in response.output:
if item.type == "reasoning":
for block in item.content:
print(block.text)The effort value can be low, medium, or high. For Gemma 4 E2B specifically, always use high to prevent reasoning text from leaking into the final answer.
For multi-turn conversations, only pass back final answers in the message history. Do not replay prior reasoning items to the model, as this degrades response quality.
Recommended sampling parameters: Use temperature=1.0 and top_p=0.95 for all variants in both reasoning and non-reasoning modes.
Service Tiers
Amazon Bedrock offers three inference tiers for Gemma 4:
| Tier | Best for | Notes |
|---|---|---|
| Standard | Everyday tasks: content generation, text analysis | Default. Consistent performance, no commitment. |
| Priority | Customer-facing, real-time, latency-sensitive workloads | Up to 25% better throughput than Standard. Premium price, no reservation needed. |
| Flex | Batch jobs, model evals, background summarization | Discounted pricing. Higher latency, especially during peak traffic. |
Opt into Priority by setting service_tier="priority" on each API call. You can mix tiers within the same application.
Handling Errors and Scaling in Production
Retry logic: Configure the OpenAI SDK with max_retries to handle transient failures automatically:
python
from openai import OpenAI
client = OpenAI(
api_key="<your-short-term-bedrock-api-key>",
base_url="https://bedrock-mantle.us-east-1.api.aws/openai/v1",
max_retries=6,
)Error codes to watch:
| Error | Meaning | Action |
|---|---|---|
| HTTP 429 | Token-per-minute quota exceeded | Reduce request rate, retry with exponential backoff, or request a quota increase |
| HTTP 503 | Regional capacity under pressure | Retry with exponential backoff; consider Priority tier for sustained issues |
Traffic ramp procedure: Avoid jumping straight to your target request rate. Instead:
- Start at target rate. If you see 503 errors, cut rate by 50%.
- Keep reducing until requests succeed consistently.
- Hold at that rate for 15 minutes.
- Increase by 50%, hold for 15 minutes.
- Repeat until you reach your target.
Other production tips:
- Spread large workloads across multiple minutes rather than sending bursts.
- Use feature flags when migrating to a new model version to ramp traffic gradually.
- Send async or batch work to the Flex tier for better price-performance.
- Distribute across multiple AWS regions for resilience.
Prompt Caching
Implicit prompt caching is automatically enabled for all Gemma 4 models on Amazon Bedrock. When consecutive requests share the same prompt prefix, the model can reuse cached internal state, reducing latency at no extra cost.
To take advantage of this, put static content (system prompts, tool definitions, source documents) at the start of your prompt, and put dynamic content at the end.
Availability and Pricing
Gemma 4 is available in:
- US East (N. Virginia)
- US East (Ohio)
- US West (Oregon)
- Europe (Frankfurt)
Pricing is per token and varies by model and service tier. Check the Amazon Bedrock pricing page for current rates.
Q&A
1. Do I need to host the Gemma 4 weights myself on Amazon Bedrock?
No. Amazon Bedrock is fully managed. You do not provision infrastructure, host model weights, or operate inference stacks. You call an API and pay per token.
2. Can I use the standard OpenAI Python SDK to call Gemma 4 on Bedrock?
Yes. You only need to change the base_url to the bedrock-mantle endpoint and update the model parameter to the Gemma 4 model ID. Everything else stays the same.
3. Are my prompts used to train Gemma 4 or any other model?
No. Amazon Bedrock does not use your prompts or completions to train models, and your content is not shared with third parties, including Google DeepMind.
4. What is the difference between the Chat Completions API and the Responses API?
Chat Completions uses a messages list and is best for multi-turn conversations and client-side tool-calling loops. The Responses API uses a single input field and is suited for single-turn generation and accessing the model's reasoning output via output_text.
5. When should I enable reasoning mode?
Enable reasoning mode for complex multi-step tasks like math problems, logic puzzles, and detailed coding tasks. It increases latency and token usage, so avoid it for simple or time-sensitive requests. For the E2B variant, always use reasoning_effort=high.
6. What image formats and sources does Gemma 4 support?
It supports images sent as base64-encoded data URLs (e.g., data:image/png;base64,...) or as Amazon S3 URLs (s3://bucket/file.png). Public https:// URLs from the internet are not supported.
7. What is the Gemma 4 26B-A4B and why is it cost-efficient?
It is a mixture-of-experts model with 25.2B total parameters, but only 3.8B parameters are active per token during inference. This means its compute cost and latency are similar to a 4B dense model, while retaining the knowledge capacity of a much larger one.
8. How do I handle throttling errors in production?
Configure the OpenAI SDK with max_retries=6 to automatically retry with exponential backoff. For sustained 503 errors, reduce your request rate using the ramp procedure described above, or upgrade latency-sensitive traffic to the Priority tier.
9. Does prompt caching cost extra?
No. Implicit prompt caching is automatically enabled at no extra cost. Cache hits reduce latency for requests with matching prompt prefixes, and cached input tokens do not count against your input-token quota.
10. How do I choose between Standard, Priority, and Flex tiers?
Use Standard for everyday tasks with no urgency. Use Priority for customer-facing and real-time workloads where response speed matters and you can absorb the premium price. Use Flex for background jobs, evaluations, and batch processing where higher latency is acceptable in exchange for lower cost.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there.