Appearance

What Is "Deployment Overhang" in AI Development? Understanding the Shift in Human Rigor
Understand what deployment overhang means for software teams, how AI-driven development shifts human rigor upstream and downstream, and how to adapt your SDLC.
Your AI coding agent just shipped a feature in twelve minutes. No meetings, no back-and-forth, no waiting on a teammate in another time zone. The code compiles. The tests pass. Everything looks like progress.
But here's the catch: that same agent could probably handle a much bigger chunk of your workflow on its own. Your tools are more capable than your process allows them to be. That gap has a name, and it is reshaping how engineering teams think about control, trust, and where careful thinking actually needs to happen.
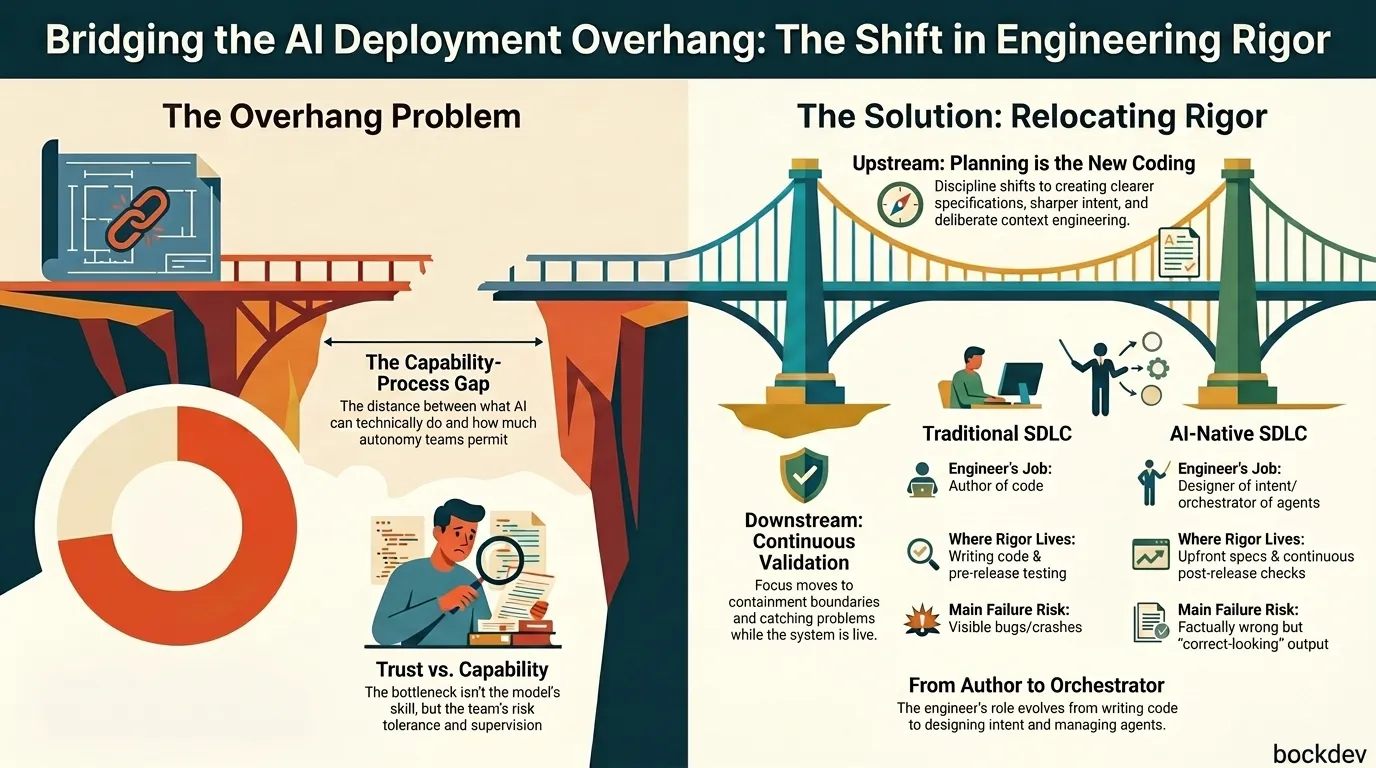
This gap is called the "deployment overhang," and understanding it is the key to using AI well instead of just using it fast.
What Is Deployment Overhang?
Deployment overhang is the gap between what AI developer tools can technically achieve and the level of autonomy an engineering organization actually permits them to have. It represents a process bottleneck where team habits and review gates fail to match AI capabilities.
It's not a capability problem. The model is often ready. It's a trust and process problem. Your review steps, approval gates, and team habits haven't caught up to what the tool is capable of.
A simple way to picture it:
| Side | What it looks like |
|---|---|
| Tool capability | AI agents can code, self-debug, and run for long sessions with little input |
| Organizational readiness | Teams still require human review for the large majority of code changes |
| The gap | This mismatch is the deployment overhang |
According to LTM's SDLC AI Radar 2026, most organizations in 2026 face exactly this gap: advanced AI programmers can independently code and self-debug for lengthy sessions, but organizations still require human review for around 73% of code changes and limit irreversible actions to near-zero cases.
So the tool isn't the bottleneck anymore. Your processes are.
Why the AI Deployment Overhang Exists in Teams
Three things keep the overhang in place:
- Risk tolerance hasn't changed as fast as model capability. Letting an agent merge code without review feels riskier than it actually might be, because trust is built slowly.
- Few teams have practiced supervising AI at scale. Reviewing one AI suggestion is easy. Supervising a fleet of agents working in parallel is a new skill most engineers haven't built yet.
- Failure modes are different now. AI output can look completely correct and still be subtly wrong. That uncertainty makes people cautious, and caution is what keeps the gap open.
The fix isn't to remove caution. It's to raise your team's ability to specify, monitor, and control AI, so you can close the gap deliberately instead of by accident.
The Rigor Shift: Moving Upstream to Planning & Downstream to Verification
Here's the part most people get wrong about AI-assisted development. They think AI removes the need for careful, disciplined work.
It doesn't. It relocates it.
In the old workflow, rigor lived in two places: writing the code carefully, and testing it thoroughly before release. Both of those activities took time, and that time was also when engineers were forced to think clearly about what they were building.
AI compresses that time. But the thinking still has to happen somewhere. So it moves.
Upstream, rigor now shows up as:
- Clearer specifications
- Sharper intent and acceptance criteria
- Deliberate context engineering (curating exactly what information the AI sees)
Downstream, rigor now shows up as:
- Continuous validation, not just one-time testing
- Containment boundaries (limiting what AI can touch or break)
- Runtime oversight (catching problems while the system is live, not just before launch)
As one industry framing puts it, AI doesn't remove the need for discipline, it moves it. The time saved on typing code gets reinvested in planning, reviewing, and refining. That is the whole story of the deployment overhang in one sentence: speed went up, but the demand for judgment didn't go away. It changed addresses.
Old SDLC vs. AI-Native SDLC: A Side-by-Side Comparison
| Stage | Traditional SDLC | AI-Native SDLC |
|---|---|---|
| Where rigor lives | Mostly in writing code and pre-release testing | Split between upfront specs and continuous post-release checks |
| Engineer's main job | Author of code | Designer of intent, orchestrator of agents |
| Planning vs. coding time | Days of coding, hours of planning | Planning becomes the dominant activity; coding is largely delegated |
| What gets reviewed | Each line of code, written by a known author | Large, fast-moving AI-generated changes, often without a human author to explain intent |
| Main failure risk | Bugs that crash or throw visible errors | Outputs that look correct (HTTP 200) but are factually or logically wrong |
| Productivity signal | Lines of code, story points, velocity | Defect density, rework rate, lead time to real value |
This table captures why so many teams feel like they're "moving fast but not sure they're moving forward." The old signals of progress don't mean the same thing anymore.
Spec-Driven Development: How Upstream Rigor Replaces Coding
If rigor moved upstream, the clearest proof is the rise of spec-driven development (SDD). Instead of jumping straight into code, teams now write a structured specification first, and the AI builds from that.
A basic SDD workflow looks like this:
specify → describe what you're building and why (goals, constraints, edge cases)
plan → define technical constraints (stack, patterns, architecture)
tasks → break the plan into small, testable work items
implement → let the AI agent execute against the spec, one task at a time
verify → check the output against the original spec, not just "does it run"A minimal spec file might look like this:
markdown
# Feature: Invoice reminder emails
## Goal
Reduce unpaid invoices by sending reminders before due dates and after missed payments.
## Success criteria
- Email is sent 3 days before due date.
- Email is sent again 1 day after due date if unpaid.
- Users can disable reminders from settings.
## Non-goals
- No SMS reminders in this version.
## Edge cases
- Customer has no email on file.
- Invoice is paid between the scheduled send and the actual send time.This kind of file gives the AI agent something precise to work against, and it gives your team a clean point to review before any code is written. It's also common to keep standing rules in a file the AI reads on every run:
markdown
# AGENTS.md
## Always
- Run the full test suite before marking a task complete
- Follow existing naming conventions in /src
## Ask first
- Changing any public API signature
- Modifying database schema
## Never
- Deleting files outside the /scratch directory
- Committing directly to mainThis "Always / Ask First / Never" pattern is a simple way to encode exactly where human judgment still needs to sit, even as more execution shifts to the agent.
Directory Structure for a Spec-Driven Project
Here's roughly how a spec-driven project tends to be organized:
my-project/
├── AGENTS.md # standing rules for any AI agent working in this repo
├── specs/
│ ├── invoice-reminders.md # one spec per feature
│ └── user-auth.md
├── plans/
│ └── invoice-reminders-plan.md
├── src/
│ └── ... # actual application code
├── tests/
│ └── ...
└── README.mdKeeping specs and plans as their own files, separate from the code, makes it easy for both humans and AI agents to check whether the implementation still matches the original intent.
What "Downstream Rigor" Looks Like in Practice
Upstream planning solves half the problem. The other half is catching things after the AI has already produced output. A few practical patterns:
Hallucination containment. Don't try to eliminate every mistake. Instead, limit how much damage one mistake can do. Route high-impact actions (payments, deployments, access changes) through an approval step, and let only low-risk tasks run automatically.
text
if action.risk_level == "high":
require_human_approval(action)
else:
execute(action)
log_for_audit(action)Boundary enforcement at runtime. Don't just write a policy document. Enforce it in code, so an agent technically cannot perform a forbidden action, rather than just being asked not to.
text
allowed_tools = ["read_file", "run_tests", "create_pull_request"]
blocked_tools = ["delete_repo", "force_push", "modify_prod_database"]Continuous evaluation instead of one-time testing. Set a measurable target before the AI starts work, and keep checking against it after launch, not just before.
text
eval_target = {
"task": "customer support reply classification",
"minimum_accuracy": 0.92,
"check_frequency": "daily"
}These aren't exotic techniques. They're the same discipline software engineering has always needed, just aimed at a new kind of risk.
3 SDLC Patterns to Close the Deployment Overhang
Closing the deployment overhang doesn't mean removing human review. It means raising the skill level of the humans doing the supervising, so review can scale with the AI's output.
A few patterns that are gaining traction:
- Conductor pattern: one engineer directs a single AI agent through a task, reviewing each step. This is the entry point for most teams.
- Orchestrator pattern: an engineer manages multiple agents working in parallel, each with a defined role (one plans, one codes, one tests). This requires more experience but unlocks much higher throughput.
- Auto-approve with guardrails: low-risk, well-tested changes (like dependency patches or docs-only edits) get to skip human review entirely, while anything touching core logic still requires sign-off.
The goal across all three is the same: let autonomy expand exactly as fast as your ability to verify it expands, and no faster.
Q&A
1. What does "deployment overhang" actually mean in simple terms?
It means your AI tools can do more than your team currently lets them do. The technology is ahead of your process, not the other way around.
2. Is deployment overhang a bad thing?
Not inherently. It just means there's unused potential. The risk comes from closing the gap carelessly, by giving AI more autonomy than your verification process can support.
3. How is this different from a "capability overhang"?
Capability overhang usually refers to the gap between what a model could do in theory and what anyone has figured out how to use it for. Deployment overhang is more specific: it's the gap between what your AI tools can already do in your workflow and what your organization's process currently permits.
4. Why can't we just let AI have more autonomy right now?
Because AI systems are probabilistic. Output can look completely fine and still be subtly wrong, and that kind of failure can be silent until it causes real damage. Autonomy needs to be earned with monitoring and guardrails, not granted all at once.
5. What does it mean that "rigor moved upstream"?
It means the careful thinking that used to happen while writing code now happens while writing the specification before any code exists. Time saved on typing gets reinvested in clearer planning.
6. What does "rigor moved downstream" mean?
It means some of the discipline that used to happen in pre-release testing now happens after deployment, through continuous monitoring, runtime checks, and containment of what AI can affect.
7. What is spec-driven development, briefly?
It's a workflow where you write a clear specification first (goals, constraints, edge cases), turn that into a plan, break the plan into tasks, and only then let an AI agent write the code. The spec stays as the source of truth.
8. Do we need to throw out code review entirely?
No. Code review still matters, but it has to adapt. Reviewers now often need AI-generated summaries and test results alongside the code, since there's no human author present to explain intent the way there used to be.
9. What's a quick way to start applying this without overhauling everything?
Start with an AGENTS.md style file defining what the AI can always do, what needs a human's okay first, and what it should never do. This alone reduces a lot of unmanaged risk.
10. How do we know if we're closing the gap responsibly?
Track outcomes, not just output. If AI-generated work increases speed but rework, defect rates, or production incidents also rise, you're closing the gap faster than your verification process can support.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- SDLC AI Radar 2026 - https://www.ltm.com/insights/reports/sdlc-ai-radar-2026
- Spec Driven Development: What It Is & How to Use It - https://evangelistsoftware.com/blog/spec-driven-development-guide/
- Spec-Driven Development (SDD): The Definitive 2026 Guide - https://thebcms.com/blog/spec-driven-development
- Spec-driven development: Unpacking one of 2025's key new AI-assisted engineering practices - https://www.thoughtworks.com/en-us/insights/blog/agile-engineering-practices/spec-driven-development-unpacking-2025-new-engineering-practices