Appearance

AI as Judge: How Pairwise Preference Ranking Works
AI as judge uses one model to score another model's output, often by comparing two answers head to head instead of grading each one alone.
You shipped a new prompt. It feels better. But "feels better" is not a metric, and you can't have a human read 10,000 outputs every time you tweak a system prompt.
This is the wall almost every team building with LLMs hits eventually. Manual review doesn't scale, and simple metrics like BLEU or ROUGE don't capture whether an answer is actually good.
The fix that's taken over the industry is simple: use an LLM to grade the LLM. And instead of asking it to give a score out of 10, the smartest version asks it a much easier question: "which of these two answers is better?" That's pairwise preference ranking, and it's quietly become the backbone of modern AI evaluation.
What Does "AI as Judge" Actually Mean?
AI-as-judge (also written LLM-as-a-judge) means using a language model to evaluate the output of another model, instead of relying only on humans.
The judge model looks at a response (or two) and produces a verdict: a score, a label, or a preference. It can also explain why it picked that answer.
This matters because human preference evaluation gives a direct signal but is expensive, slow, and hard to reproduce. An AI judge gives you a much cheaper, faster stand-in.
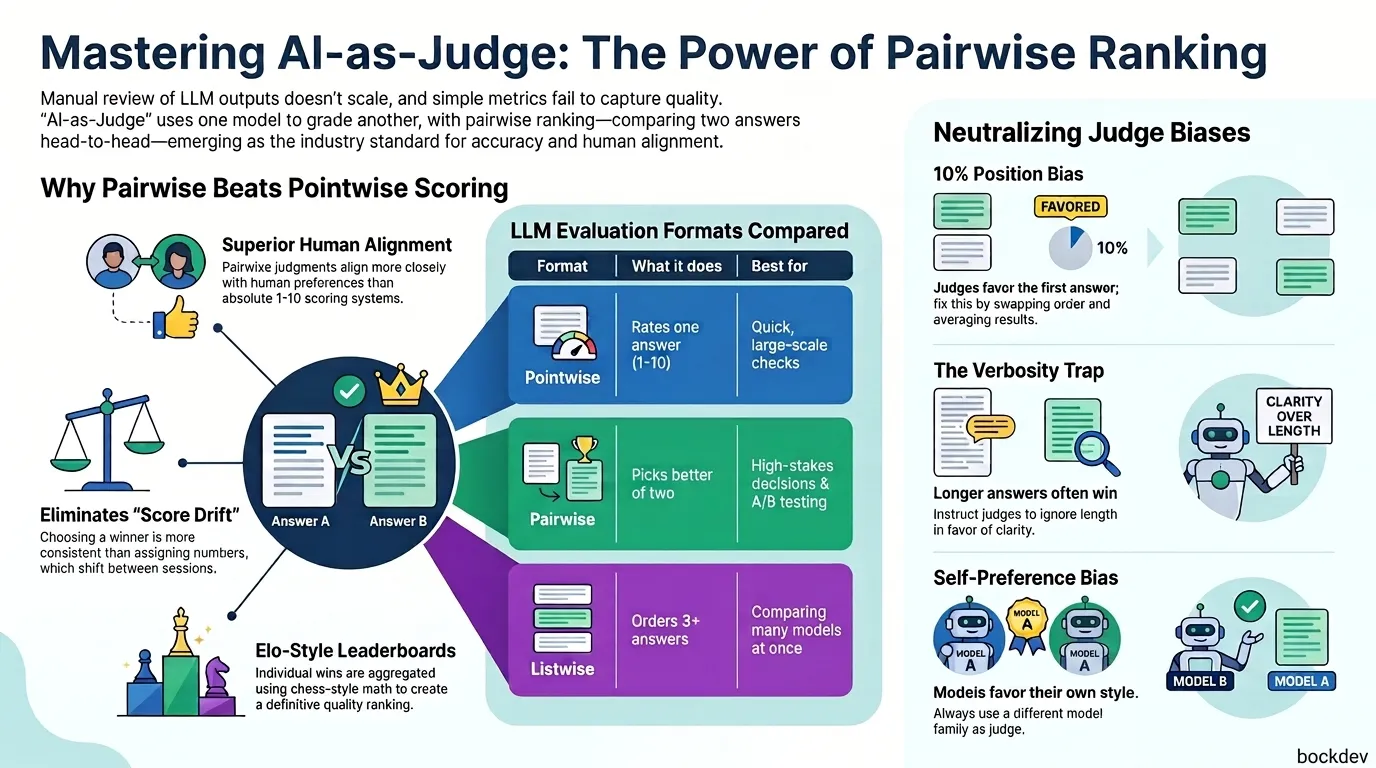
There are three common formats:
| Format | What it does | Best for |
|---|---|---|
| Pointwise scoring | Rates one answer alone (e.g. 1-10) | Quick, large-scale checks |
| Pairwise comparison | Picks the better of two answers | High-stakes decisions, A/B testing |
| Listwise ranking | Orders 3+ answers at once | Comparing many models together |
Why Pairwise Comparison Beats Pointwise Scoring
Asking a model "is this an 8 or a 9?" is harder than it sounds. Scores drift between sessions and don't compare well across different runs.
Pairwise comparison sidesteps that problem. Instead of inventing an absolute number, the judge just picks a winner between two options. That's a much more natural task for a language model.
Research backs this up: LLM and human evaluations tend to align more closely when using pairwise comparisons compared to score-based assessments. Pairwise comparative judgments also tend to be more consistent than other judging methods.
That said, pairwise isn't free. comparing multiple items requires running multiple pairwise comparisons, which raises cost and can run into ordering or position-related issues if not handled carefully.
How a Pairwise Judge Prompt Actually Works
At its core, a pairwise judge takes four things: the original question, two candidate answers, and a description of what "better" means. It returns a verdict.
Here's a basic version using the Anthropic API:
python
import anthropic
client = anthropic.Anthropic()
def pairwise_judge(question, response_a, response_b, criteria):
prompt = f"""You are an impartial judge. Compare the two responses below
based only on: {criteria}
Question: {question}
Response A:
{response_a}
Response B:
{response_b}
Which response is better? Reply with only "A" or "B", then a one-sentence reason.
"""
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=200,
messages=[{"role": "user", "content": prompt}]
)
return message.content[0].text
result = pairwise_judge(
question="Explain recursion to a beginner.",
response_a="Recursion is when a function calls itself...",
response_b="Recursion: f(n) = f(n-1) + base case. See also: recursion.",
criteria="clarity and helpfulness for a beginner"
)
print(result)A few things matter here:
- Keep the grading criteria explicit. Vague instructions invite vague judgments.
- Ask for a short reason. It forces the model to justify the pick, not just guess.
- Set a low
temperaturefor more consistent verdicts run to run.
The Biases You Need to Know About
An AI judge isn't neutral by default. A few well-documented biases show up in almost every untreated setup:
Position bias. The judge tends to favor whichever answer appears first (or last, depending on the model), regardless of quality. GPT-4 shows roughly a 10% preference for the first position across diverse tasks.
Verbosity bias. Longer answers often win even when they're not actually better. Length reads as effort, and effort reads as quality, even though sometimes the longer answer genuinely is better.
Self-preference bias. A model tends to rate outputs from its own model family more favorably, likely because it recognizes its own stylistic patterns.
Calibration drift. Judge behavior can shift silently when the underlying model version changes, even if your prompt and rubric stay the same.
| Bias | What happens | Typical fix |
|---|---|---|
| Position | First/last answer wins by default | Swap order, run twice, average |
| Verbosity | Longer answer wins by default | Add explicit length-neutral instruction |
| Self-preference | Judge favors its own model family | Use a different model as judge |
| Calibration drift | Scores shift after a model update | Pin model version, re-check against humans |
How to Reduce Bias in Practice
The single most effective fix for position bias is also the simplest: run the comparison twice, swapping which answer is shown first, and only trust the verdict if it's consistent both times.
python
def debiased_pairwise_judge(question, response_a, response_b, criteria):
verdict_1 = pairwise_judge(question, response_a, response_b, criteria)
verdict_2 = pairwise_judge(question, response_b, response_a, criteria)
pick_1 = "A" if verdict_1.strip().startswith("A") else "B"
# verdict_2 has positions swapped, so flip the labels back
pick_2 = "B" if verdict_2.strip().startswith("A") else "A"
if pick_1 == pick_2:
return pick_1 # consistent result, trust it
return "tie" # inconsistent, treat as no clear winnerFor verbosity bias, add a direct instruction to the prompt: "Evaluate based only on accuracy and clarity, not length." It won't eliminate the bias, but it meaningfully reduces it.
For self-preference bias, use a judge from a different model family than the one being evaluated whenever possible.
How Rankings Are Built From Many Comparisons
A single pairwise comparison only tells you A beat B once. To rank a whole set of models or prompt variants, those comparisons get aggregated, usually with an Elo-style or Bradley-Terry scoring system, the same math used to rank chess players.
Each comparison updates a "rating" for each candidate. Win more comparisons (especially against strong opponents), and your rating climbs.
Round 1: Prompt_A vs Prompt_B → Prompt_A wins → ratings update
Round 2: Prompt_A vs Prompt_C → Prompt_C wins → ratings update
Round 3: Prompt_B vs Prompt_C → Prompt_B wins → ratings update
...
Final: Prompt_C (1542) > Prompt_A (1498) > Prompt_B (1460)This is essentially how public leaderboards for chatbots work: thousands of anonymous pairwise votes get rolled up into a single ranked list.
A Typical Evaluation Pipeline Layout
If you're setting this up as a repeatable system rather than a one-off script, a typical project structure looks like this:
eval-pipeline/
├── prompts/
│ ├── judge_prompt.txt
│ └── rubric.yaml
├── data/
│ ├── questions.jsonl
│ └── human_labels.jsonl
├── src/
│ ├── judge.py # pairwise_judge + debiasing logic
│ ├── elo.py # rating aggregation
│ └── run_eval.py # orchestrates comparisons
└── reports/
└── results.csvKeeping the rubric and prompt as separate files (not hardcoded strings) makes it much easier to version them and re-run evaluations when you update your judge model.
When Should You Trust an AI Judge?
Treat an AI judge the way you'd treat a new hire: useful, but not unsupervised on day one.
Calibrate it against a small set of human-labeled examples first. A commonly cited target is 75-90% agreement with human labels before trusting the judge on unlabeled data. Below that range, the judge tends to add more noise than signal. If it disagrees often, fix the rubric before trusting the volume.
It's also worth re-checking that calibration periodically, especially after switching judge models or prompt versions, since drift can happen quietly.
Q&A
1. What is "AI as judge" in simple terms?
It's using one AI model to evaluate the output of another AI model, instead of relying only on human reviewers.
2. Why use pairwise comparison instead of just scoring 1-10?
Picking a winner between two answers is an easier, more natural task for a model than assigning an absolute score, and it tends to align better with human judgment.
3. Can the same model judge its own answers?
It can, but it's risky. Models tend to rate their own outputs more favorably, so using a different model family as judge is generally safer.
4. What is position bias?
It's the tendency of a judge to favor whichever answer appears first (or last) in the prompt, independent of actual quality.
5. How do you fix position bias?
Run the same comparison twice with the order swapped, and only trust the result if both runs agree.
6. Does a longer answer usually win?
Often, yes, even when it shouldn't. This is called verbosity bias, and it can be reduced by explicitly telling the judge to ignore length.
7. What's the difference between pointwise, pairwise, and listwise evaluation?
Pointwise scores one answer alone, pairwise picks a winner between two, and listwise ranks three or more answers at once.
8. How are pairwise results turned into a ranking?
Through rating systems like Elo or Bradley-Terry, the same approach used to rank chess players, where wins against strong opponents count more.
9. How do I know if my AI judge is reliable?
Compare its verdicts against a human-labeled sample. A commonly cited target is 75-90% agreement with human labels before scaling the judge up to unlabeled data.
10. Does the judge model ever need to be re-checked?
Yes. Updating the model version, prompt, or rubric can quietly shift its behavior, so periodic re-calibration against human labels is good practice.
My SaaS
Acluebox
Build modular and reusable system prompts with my SaaS,
Acluebox
. Also, free prompt template generators there. References
- LLM as a Judge - https://arize.com/llm-as-a-judge/
- Mingyuan Xu, et al (2026). A Judge-Aware Ranking Framework for Evaluating Large Language Models without Ground Truth – https://arxiv.org/pdf/2601.21817
- Tuhina Tripathi, et al (2025). Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation – https://arxiv.org/pdf/2504.14716
- Jiawei Gu, et al (2026). A survey on LLM-as-a-judge – https://www.sciencedirect.com/science/article/pii/S2666675825004564